搜索到
36
篇与
» AI
的结果
-
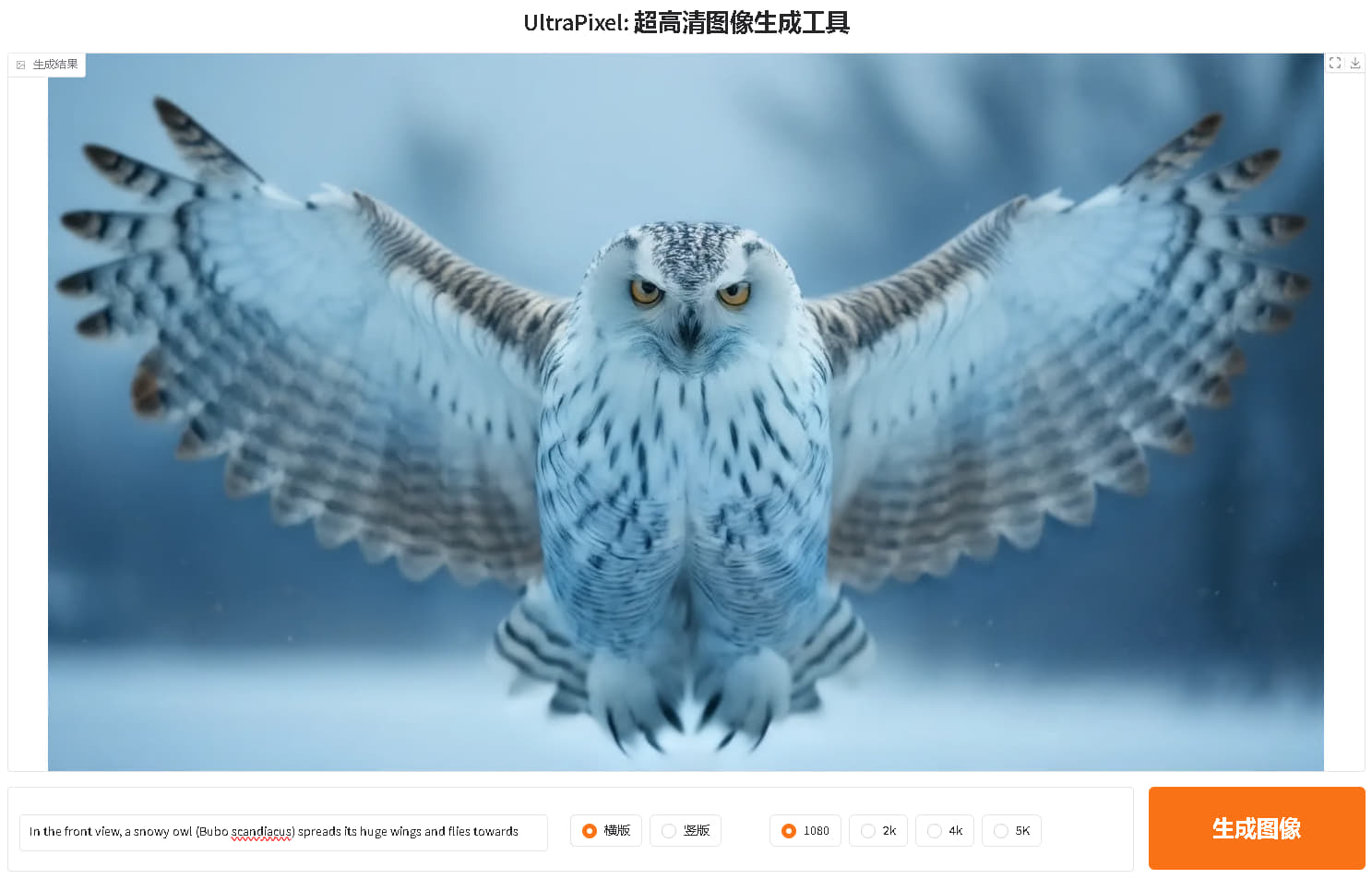
 基于FLUX.2-klein-base-4b二创的键盘摄影大师-V5 基于FLUX.2-klein-base-4b二创的键盘摄影大师-V5 源自jian27 [https://www.jian27.com/html/2573.html](https://www.jian27.com/html/2573.html) 5.1 增加去掉反光功能,不能100%去除反光,这个应该有常识 5.2 修复输出图片变形问题 5.3 增加载入右图到输入框,让生成的图片作为底图重新编辑,例如去除文字后,再编辑图片等等场景 5.4 修复单张出图无法载入问题,修复载入图片是之前的旧图问题 5.5 修复页面遮挡问题,1080 27寸显示器,按钮被遮挡一部分,已修正 本工具模型为4B版本,需要12gb显存运行,最低要求3060 12gb版本,或4060 16gb版本等等 内置53种常用预设,你不会找到其他版本有这么多预设了,全部精挑细选,从一百多中预设中只保留这些效果最好的 由于模型原因,有时候并不能生成满意的照片 相同的照片,每个预设都生成一次,也有根本没效果的 这个就是俗称的抽卡,有时候效果非常好,有时候几乎没效果还更差 这个模型是4B参数的,不要与那些各家在线模型相比,天壤之别,在线模型可以达到1000B参数 目前来说,有这个效果,我个人已经非常非常满意了 出图首选尺寸依然1024 超过这个尺寸,可能多手多脚,这个不解释,懂的都懂 5090 文生图3秒,图片编辑 7秒 均为1024短边边长 可以生成1600*1600分辨率图片,效果一般 小于12gb显存的,不用下载,无法运行!!!!!!!!!!!!!!内存16gb或以上就行 提供试用版,需要联网验证,自动验证的,联网即可 验证后提供72小时试用许可,试用期间不限制张数,全功能试用 99元收费后提供断网离线验证许可,离线版不限制时间 左右扩展,上下扩展,四周扩展,这几个并不是总会生效,很多时候没有效果 999提供源码(不含验证机制的源码) 版面排版极度舒适,十分适合强迫症患者服用 以下为新版截图 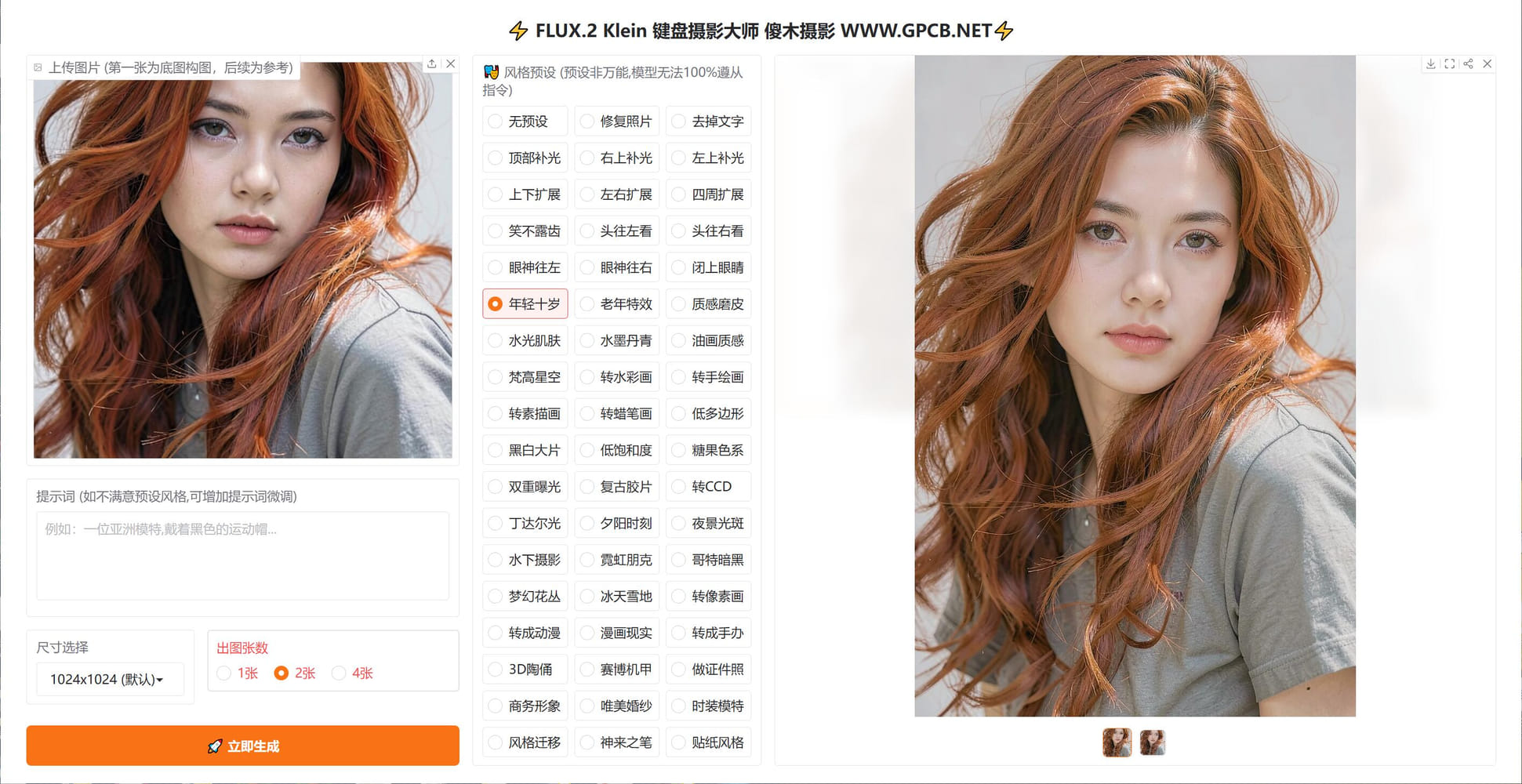 以下功能均包含,以下界面是旧版的,新版均有相应增强 超强去水印 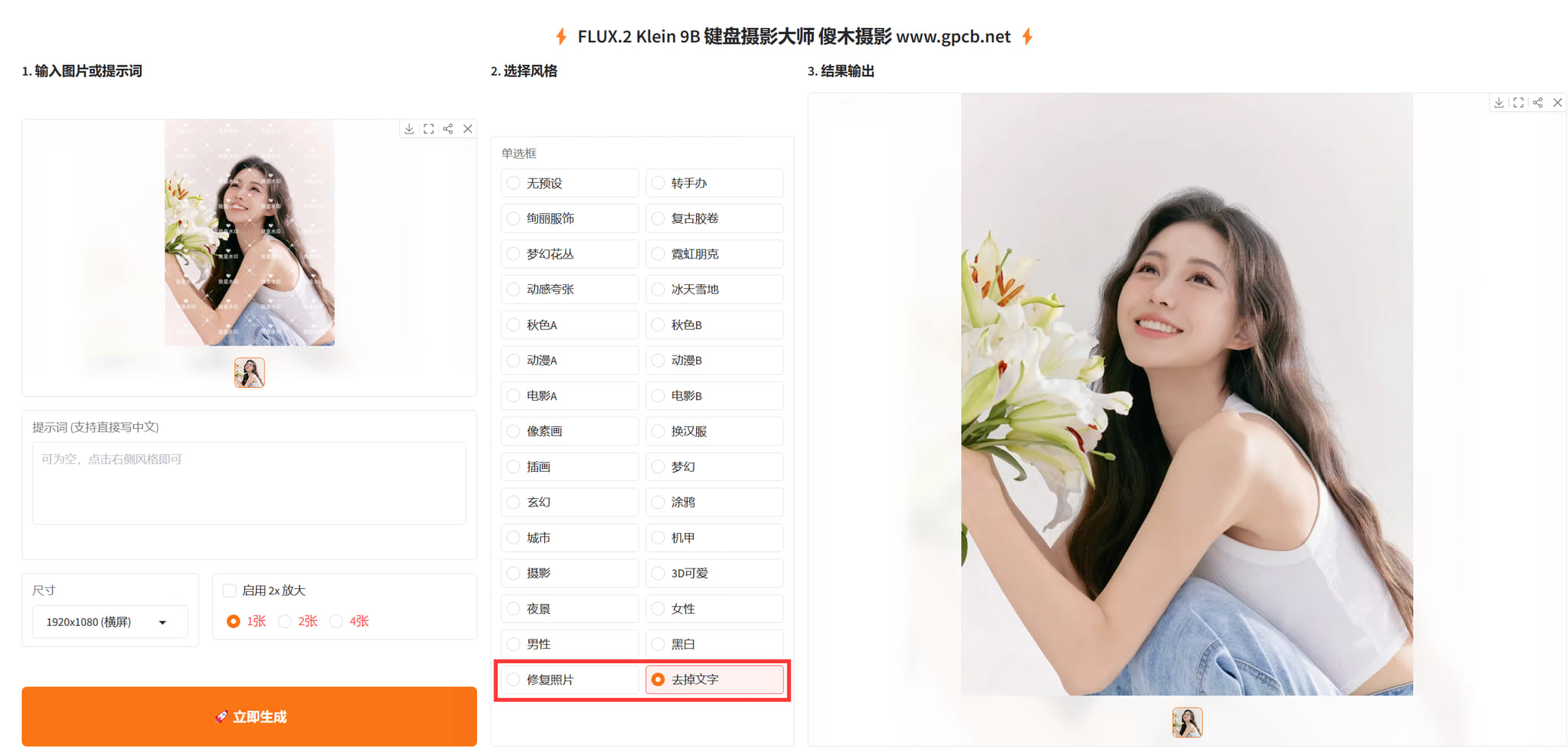 老照片修复(不限于老照片,大头贴之类的,都可以修复,可以高清还原) 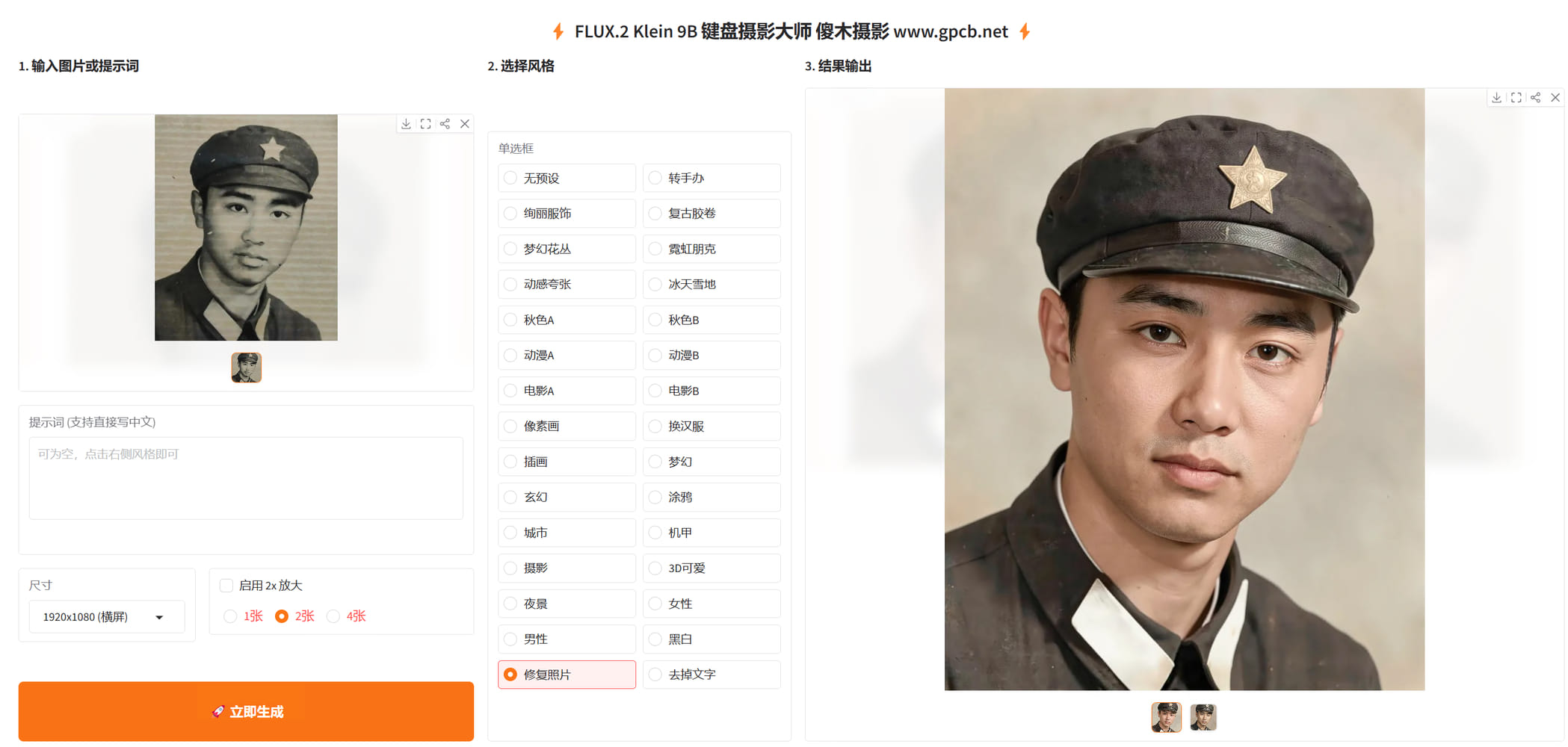 漫画,线稿,转真人 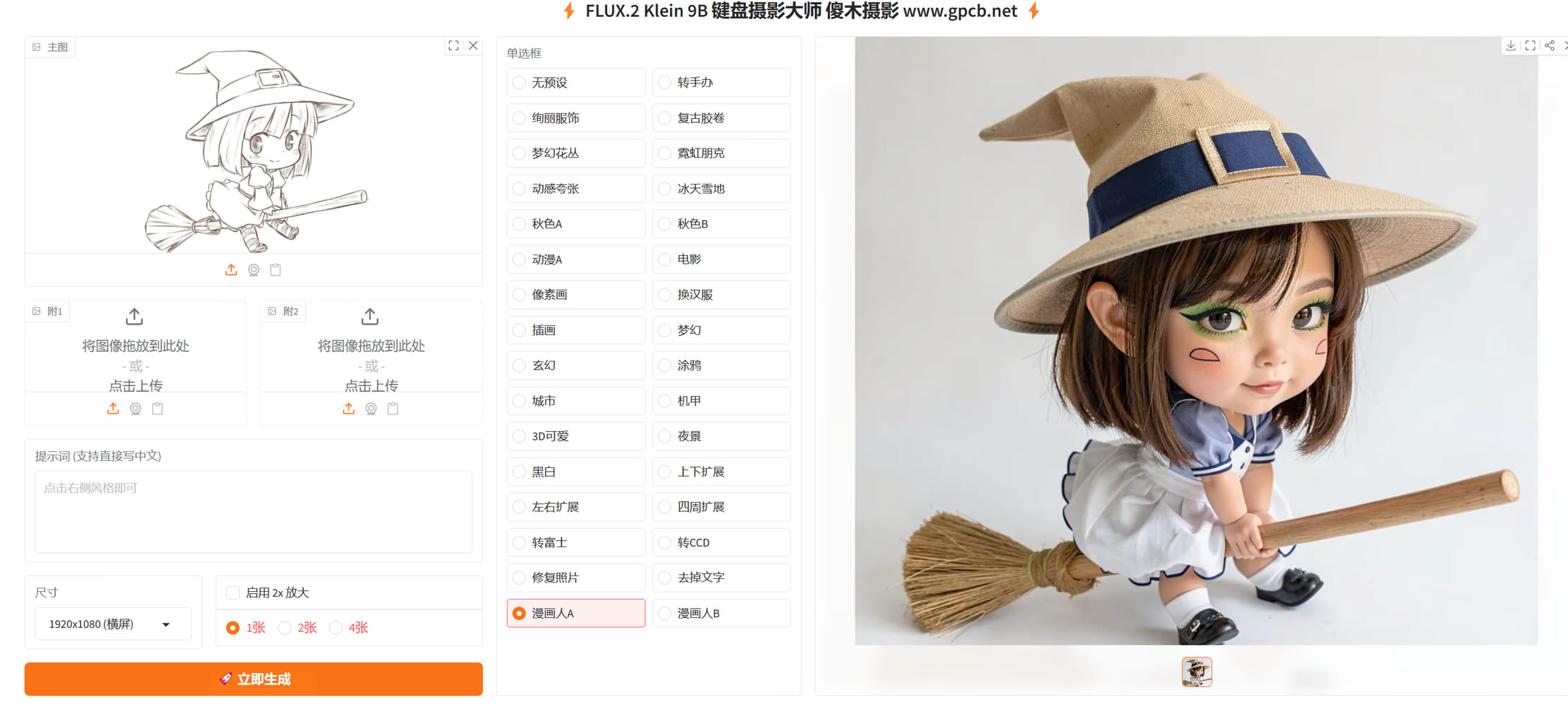 链接: [https://pan.baidu.com/s/19awjTvDpGvhpjdaw8Rzd7Q?pwd=gpcb](https://pan.baidu.com/s/19awjTvDpGvhpjdaw8Rzd7Q?pwd=gpcb)
基于FLUX.2-klein-base-4b二创的键盘摄影大师-V5 基于FLUX.2-klein-base-4b二创的键盘摄影大师-V5 源自jian27 [https://www.jian27.com/html/2573.html](https://www.jian27.com/html/2573.html) 5.1 增加去掉反光功能,不能100%去除反光,这个应该有常识 5.2 修复输出图片变形问题 5.3 增加载入右图到输入框,让生成的图片作为底图重新编辑,例如去除文字后,再编辑图片等等场景 5.4 修复单张出图无法载入问题,修复载入图片是之前的旧图问题 5.5 修复页面遮挡问题,1080 27寸显示器,按钮被遮挡一部分,已修正 本工具模型为4B版本,需要12gb显存运行,最低要求3060 12gb版本,或4060 16gb版本等等 内置53种常用预设,你不会找到其他版本有这么多预设了,全部精挑细选,从一百多中预设中只保留这些效果最好的 由于模型原因,有时候并不能生成满意的照片 相同的照片,每个预设都生成一次,也有根本没效果的 这个就是俗称的抽卡,有时候效果非常好,有时候几乎没效果还更差 这个模型是4B参数的,不要与那些各家在线模型相比,天壤之别,在线模型可以达到1000B参数 目前来说,有这个效果,我个人已经非常非常满意了 出图首选尺寸依然1024 超过这个尺寸,可能多手多脚,这个不解释,懂的都懂 5090 文生图3秒,图片编辑 7秒 均为1024短边边长 可以生成1600*1600分辨率图片,效果一般 小于12gb显存的,不用下载,无法运行!!!!!!!!!!!!!!内存16gb或以上就行 提供试用版,需要联网验证,自动验证的,联网即可 验证后提供72小时试用许可,试用期间不限制张数,全功能试用 99元收费后提供断网离线验证许可,离线版不限制时间 左右扩展,上下扩展,四周扩展,这几个并不是总会生效,很多时候没有效果 999提供源码(不含验证机制的源码) 版面排版极度舒适,十分适合强迫症患者服用 以下为新版截图  以下功能均包含,以下界面是旧版的,新版均有相应增强 超强去水印  老照片修复(不限于老照片,大头贴之类的,都可以修复,可以高清还原)  漫画,线稿,转真人  链接: [https://pan.baidu.com/s/19awjTvDpGvhpjdaw8Rzd7Q?pwd=gpcb](https://pan.baidu.com/s/19awjTvDpGvhpjdaw8Rzd7Q?pwd=gpcb) -
基于FLUX.2-klein_二创的_人像修饰工具_AI修图 基于FLUX.2-klein 二创的 人像修饰工具 ### **仅适用于单人人像修饰,对大头贴效果比较好** 限于当前模型,目前无法做多人的,例如两人的,以及合影的,等等,这些不是软件问题,是模型问题,这个解决不了 不限制最高像素,4000w像素输入,4000w像素输出,峰值需要12gb显存 低于1024分辨率的,自动补齐1024 有单张模式,也有批量模式 33元离线授权 后续如有新版升级免费 供72小时无限制全功能试用 该项目需要12gb显存,4060 tis 16gb显卡,约60秒一张,5090 32gb显卡14秒一张,3000x4500像素的 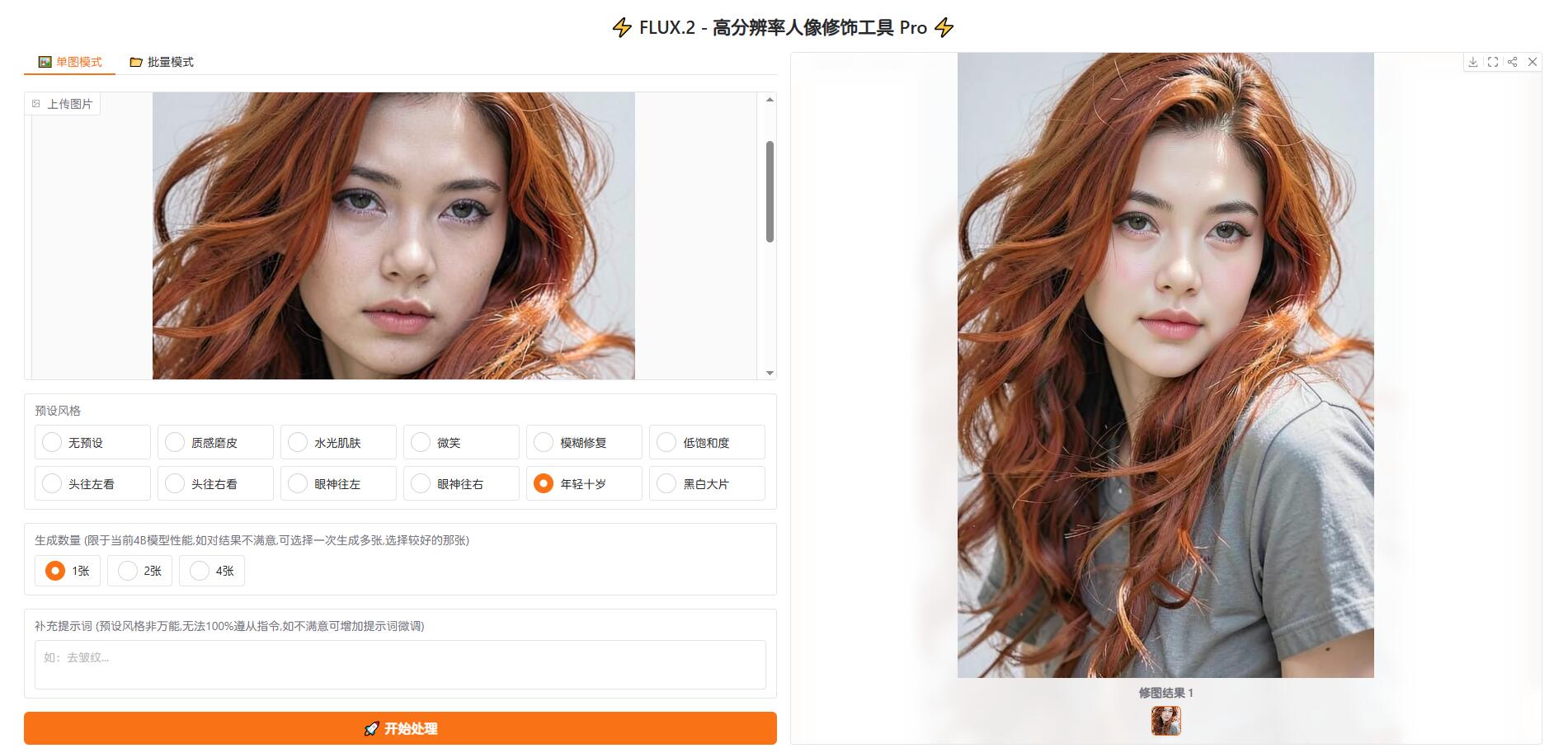 1.4版 链接: [https://pan.baidu.com/s/1gXF0c-ezJ0TFACLlZ-Xd4A?pwd=gpcb](https://pan.baidu.com/s/1gXF0c-ezJ0TFACLlZ-Xd4A?pwd=gpcb)
-
最好用的智能便签系统 最好用的智能便签系统  就一个便签,为什么叫系统? 因为这是可以团队协作的 我们部署在云端,只要有网络的地方,都可以使用 且已与企业微信集成 打开企业微信就可以直接使用 便签可以单向分享给任意注册用户,但是接收者不允许分享给第三方等等 数据记录在数据库中 因此,叫做便签系统毫无问题 由于慢慢改成了牛马系统 为回归本质,已增加图钉功能 相当于免打搅模式 点亮图钉后,启用置顶功能 优先于所有排序规则 例如新建的标签不会跑到最前面,任何情况下,点亮图钉的,都会在最前面 如果有多个便签点亮了图钉,则这些便签你可以手动调整位置排序 有完善的用户管理,有便签删除恢复,有离职便签移交  已开放注册使用,请注意不要保存重要资料,不要保存各种账号密码等等!!!!! 仅供测试 本系统对外出售,可以离线部署,需要 php > 7.0 遇到密码遗忘的,可以发送账号信息到 abpyu@139.com 邮箱 [https://gpcb.net/b/](https://gpcb.net/b/)  已增加AI功能,可以帮你快速分析任务轻重缓急,并给出合理规划建议 目前使用的阿里 qwen3-max 模型 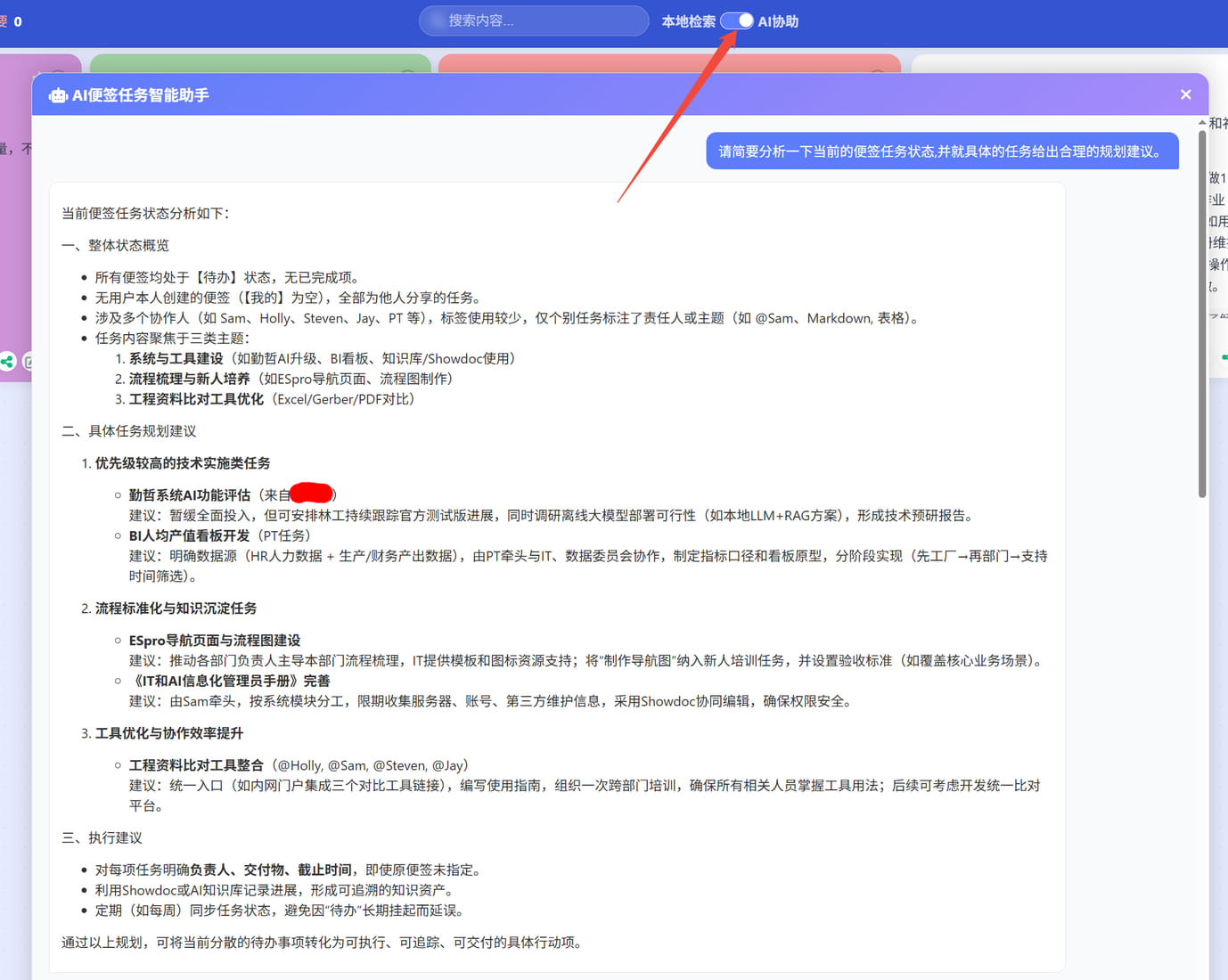
-
Z-Image-Turbo 负优化版 Z-Image-Turbo AI生图大模型 高性能AI图像生成工具 11秒一张图片 本站负优化版 主要针对18gb以上的显卡进行了优化,常驻显存17gb以上,内存占用约10gb左右 因此仅供显存富裕的用户使用 显存不足的,请到以下链接下载jian27版本 本项目来源于: [https://www.jian27.com/html/1779.html](https://www.jian27.com/html/1779.html) 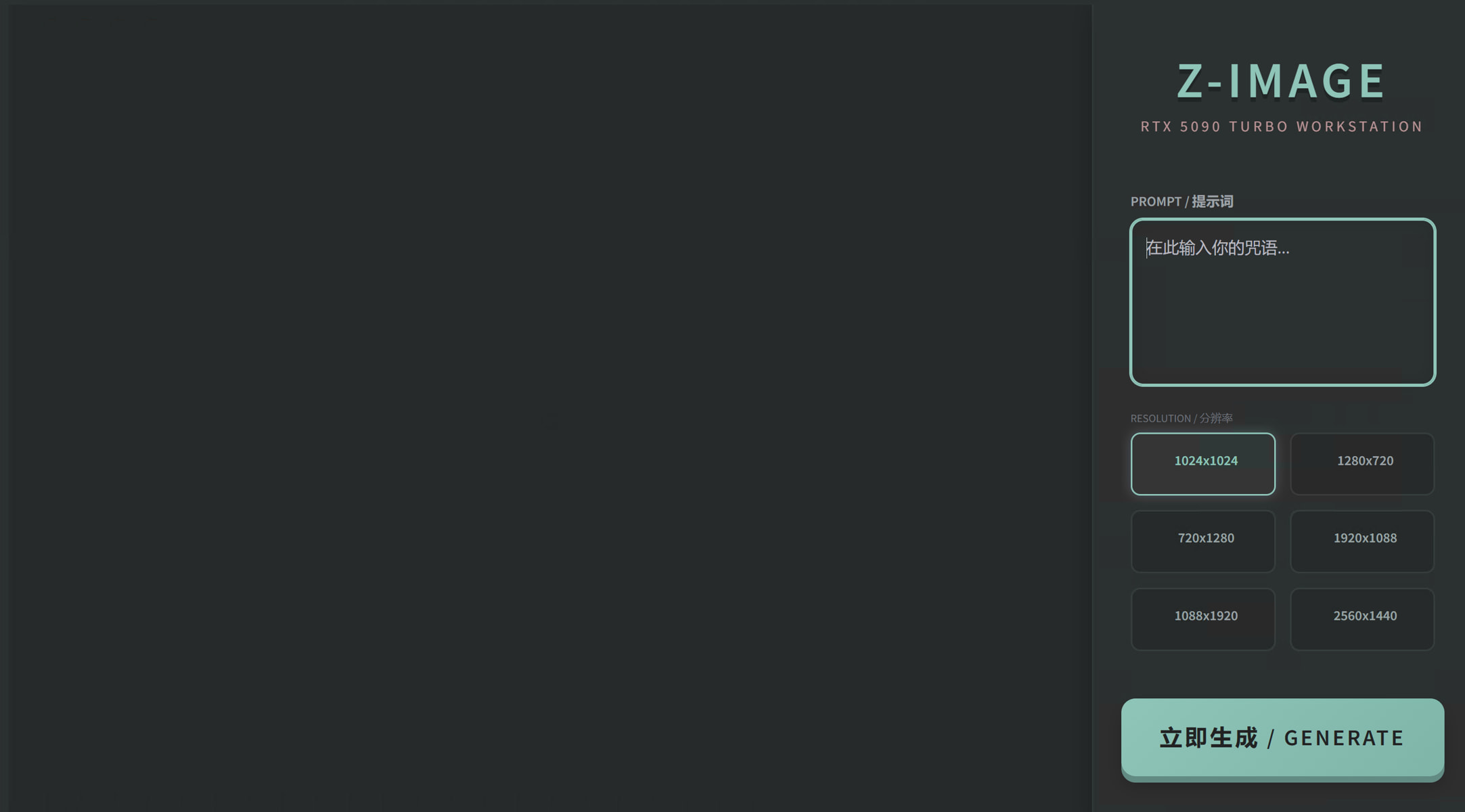 该模型依然使用的1024分辨率进行训练,因此最佳分辨率依然是1024 但是生成的人像具有非常不错的质感,与其他模型生成的硅胶皮肤大为不同 链接: [https://pan.baidu.com/s/17yNCwAk0BASxd-U_IuC9Ow?pwd=gpcb](https://pan.baidu.com/s/17yNCwAk0BASxd-U_IuC9Ow?pwd=gpcb)
-
-
-
waiNSFWIllustrious_AI生成动漫图片整合包,12G英伟达显卡即可愉快玩耍 初始化模型载入需要8gb显存,之后分解关键词等等子模型运行后总共需要消耗约12gb显存 本工具主要用来生成动漫效果 输入关键词,点击生成即可 底下有高级设置,分辨率和步骤等  jian27打包分享 [https://www.jian27.com/html/2046.html](https://www.jian27.com/html/2046.html) 本站在上述基础做了负优化 主要就是减肥,原包13gb,现在8gb 仅提供百度网盘连接 回复后,刷新可见 隐藏内容,请前往内页查看详情