


搜索到
40
篇与
AI
的结果
-
 对话式3D建模,CAD Chat 对话式3D建模,CAD Chat 先看图 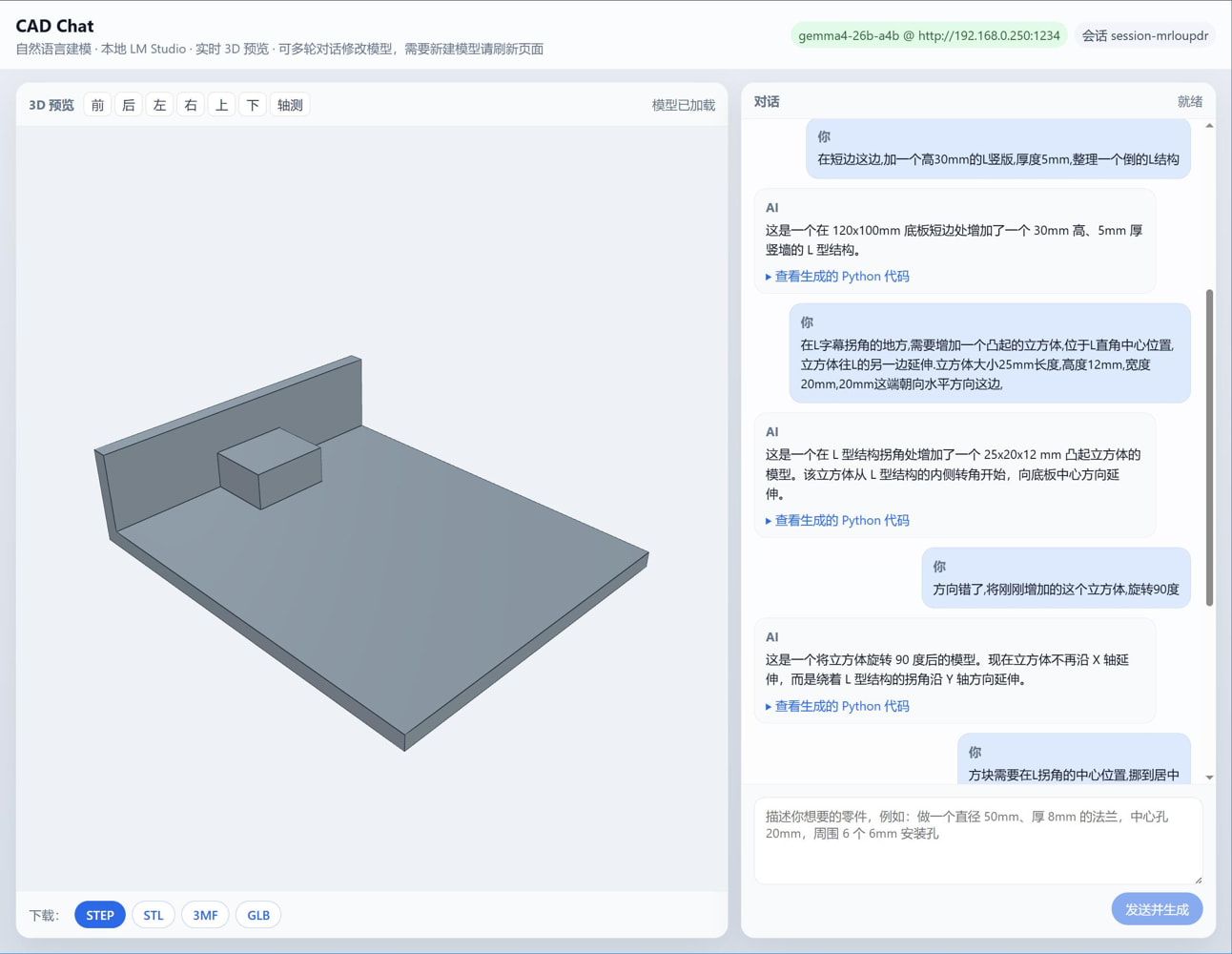 以下为开源项目地址 [https://github.com/earthtojake/text-to-cad](https://github.com/earthtojake/text-to-cad) 本项目根据上述项目重构而来 尚在完善中 原项目每次对话生成一个项目 我这个可以多次对话来修正模型 正在计划投递参考图,看看能不能照葫芦画瓢 上传参考图,给出基本信息,即可输出大致形态,之后再多次对话进行微调 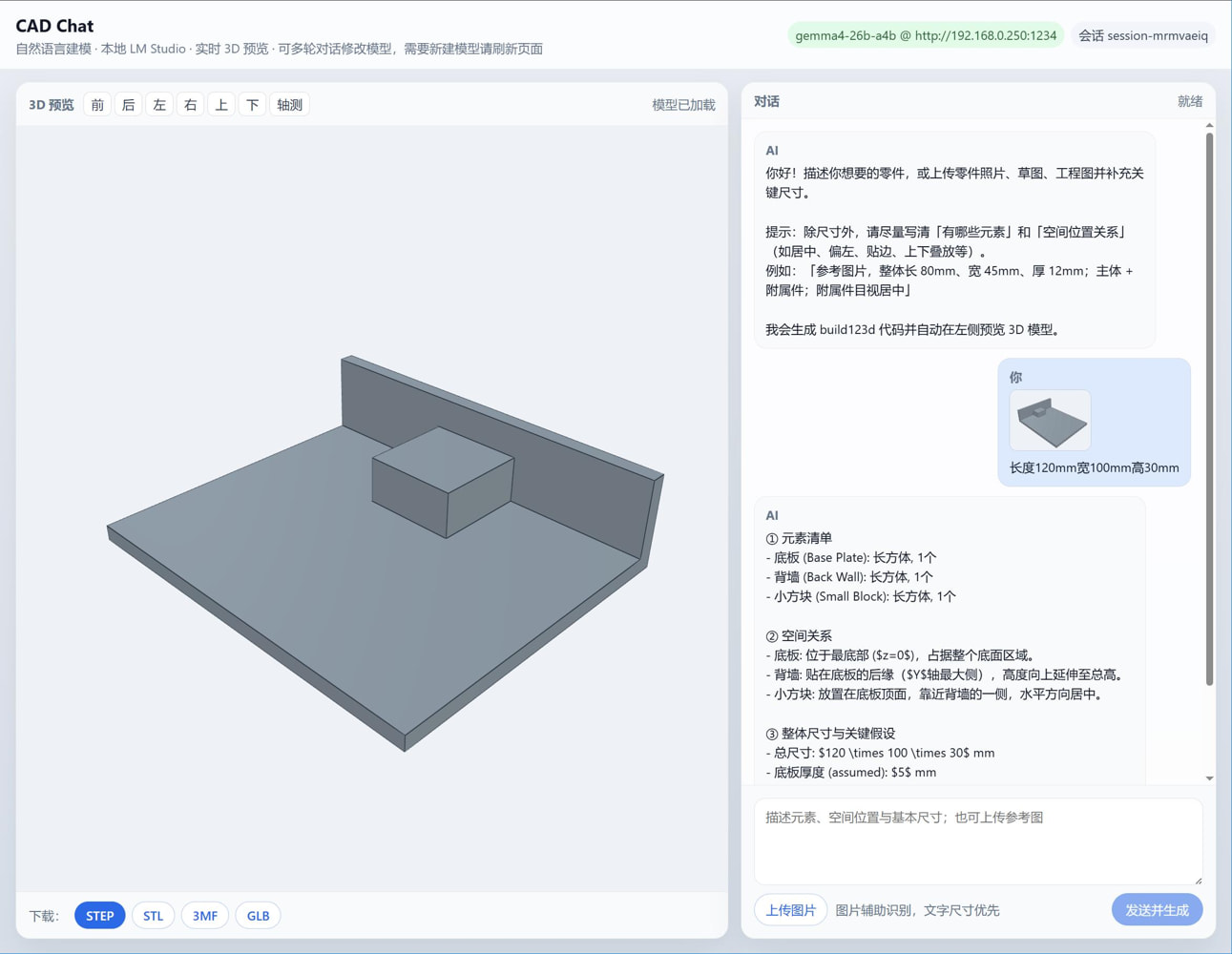 目前尚无实际生产能力,仅为验证自然语言建模能力 不提供下载
对话式3D建模,CAD Chat 对话式3D建模,CAD Chat 先看图  以下为开源项目地址 [https://github.com/earthtojake/text-to-cad](https://github.com/earthtojake/text-to-cad) 本项目根据上述项目重构而来 尚在完善中 原项目每次对话生成一个项目 我这个可以多次对话来修正模型 正在计划投递参考图,看看能不能照葫芦画瓢 上传参考图,给出基本信息,即可输出大致形态,之后再多次对话进行微调  目前尚无实际生产能力,仅为验证自然语言建模能力 不提供下载 -
视频水印去除工具,台标去除工具 加载视频文件夹 框选需要出去的图案 不要框选的太大,也不要太小 目前只能固定区域 对动画片效果比较好 其他视频可能差些 效率很高 3分半视频,20秒除去 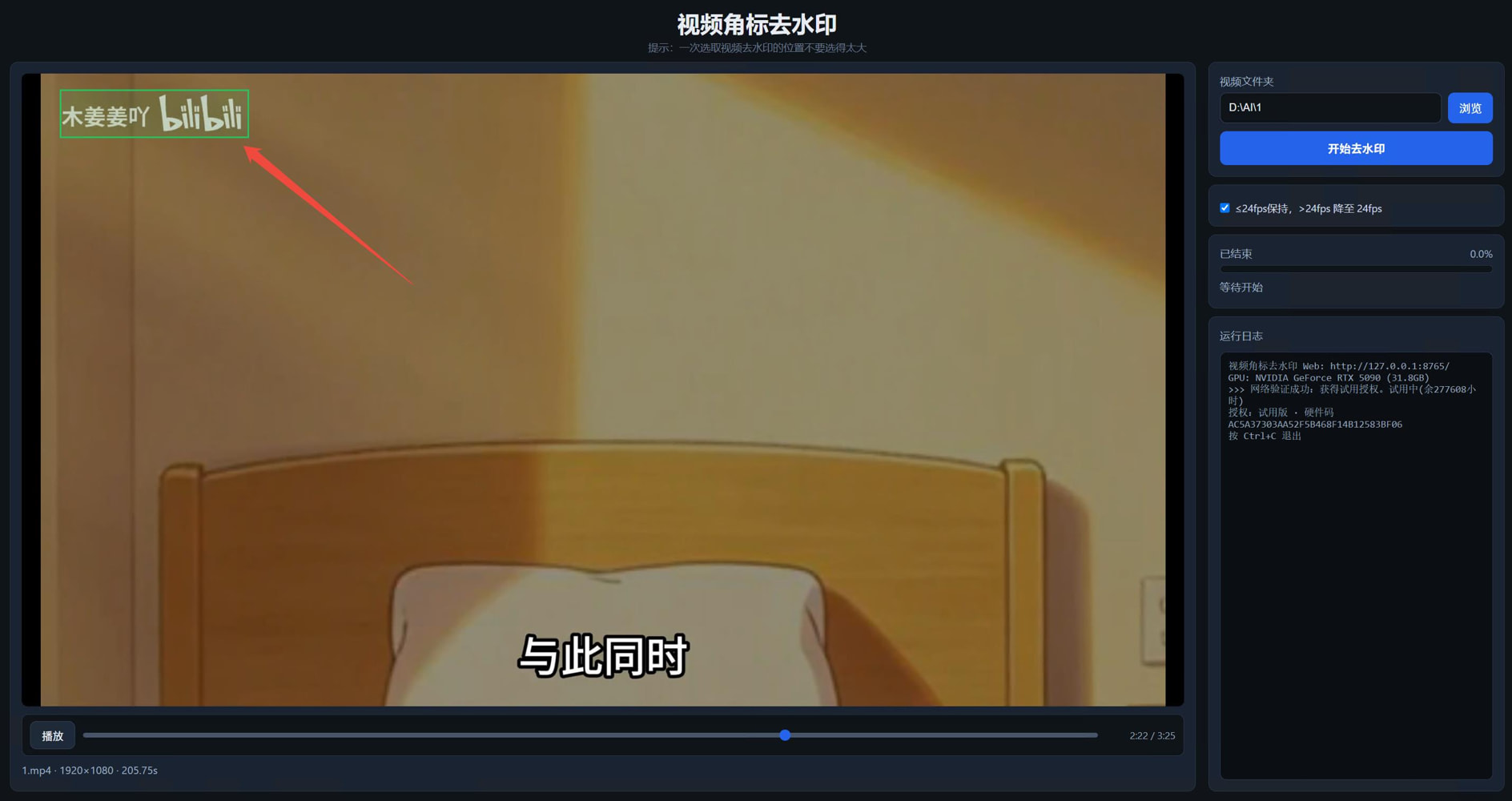 链接:[https://pan.baidu.com/s/1qD6pz0LC_9uNhDmrFxHFJw?pwd=gpcb](https://pan.baidu.com/s/1qD6pz0LC_9uNhDmrFxHFJw?pwd=gpcb) 供72小时全功能试用 99包年 需在线验证 199 不限制时长 需在线验证 如需离线不限时长授权666 一台机,绑定硬件
-
音频转字幕自动翻译一条龙 音频转字幕自动翻译一条龙 更新 集成了sensevoice-small模型 删除了whisper-large-v3-turbo模型 关于效率 194分钟音频 whisper-large-v3-turbo 114秒 输出字幕 whisper-large-v3 408秒 自带英文字幕输出 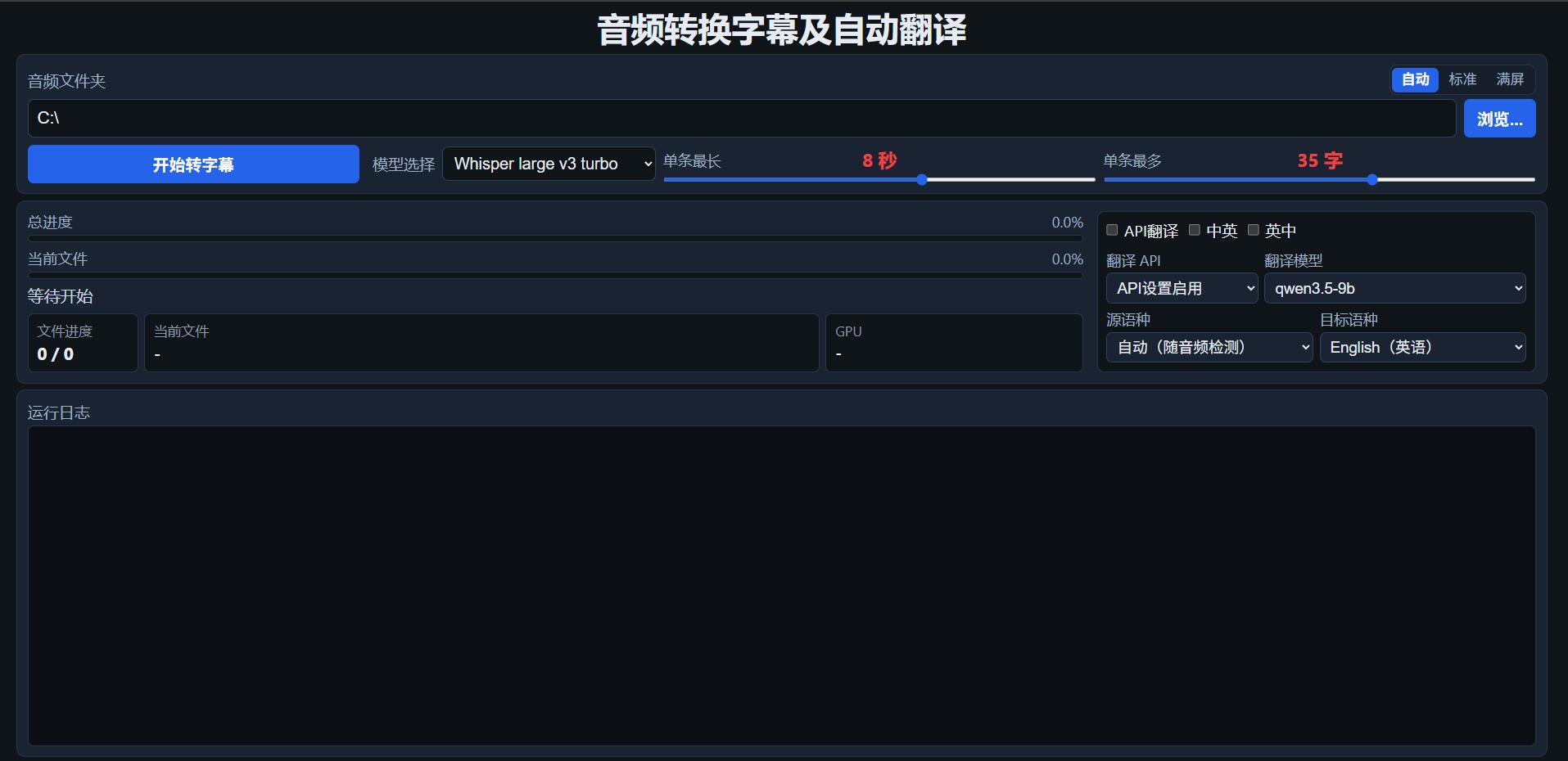 API常见的都有,包括两个本地的,以下截图不全 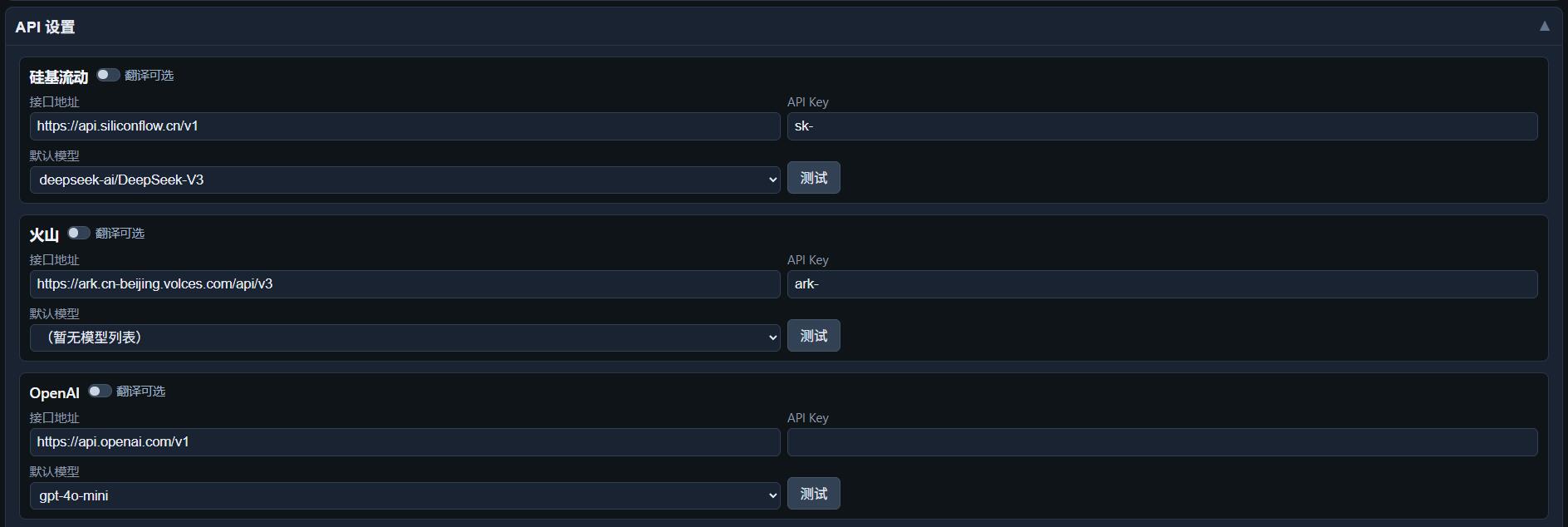 一、软件简介 本工具将文件夹内的音频/视频批量转成 SRT 字幕,可选 API 翻译或 Whisper 内置译英 设置好API服务后,勾选API翻译时,转出字幕会自动翻译成你设置的目标语言,无需其他设置 Whisper 内置译英,无需API设置即可直接将任意语言输出为英语字幕 二、运行前准备 1. 硬件 - 建议使用 NVIDIA 显卡(CUDA),转写速度明显快于 CPU。 - 显存建议 ≥ 6GB(large 级模型量化版约 3GB/路)。 2. 授权 - 首次启动会验证正式授权 license.key 或在线试用(全功能72小时试用)。 - 试用/授权失败时,控制台会显示机器码,需联系我获取授权文件 - 正式版费用说明:200元,在线限时长.350元,离线授权,断网可用 3. 启动方式 - 双击傻木摄影.exe运行 - 控制台出现 http://127.0.0.1:8765/ 后,浏览器会自动打开; 三、界面操作(逐步说明) 【第 1 步】选择音频文件夹 - 在「音频文件夹」输入路径,或点「浏览…」选择。 - 程序只处理该文件夹根目录下的文件,不递归子文件夹。 - 支持格式:.mp3 .wav .m4a .flac .aac .ogg .wma .mkv .mp4 【第 2 步】选择布局(右上角) - 自动:屏幕物理宽度 ≥ 2200px 居中显示,否则全屏 - 标准:固定居中宽度 - 满屏:界面横向铺满 【第 3 步】选择模型 - 在「模型选择」下拉框中选择(见第四节两个模型的区别)。 【第 4 步】调整字幕参数(默认参数已最佳化,不建议调整) - 单条最长:每条字幕最长持续时间(默认 8 秒) - 单条最多:每条字幕最多字数(默认 35 字) - 数值越大,单条字幕越长、行数越少;越小则切分更碎。 【第 5 步】翻译相关选项(可选,见第五节) - 右侧勾选区可配置 API 翻译、双语对照、Whisper 自翻等。 【第 6 步】配置 API(需要翻译时) 1. 展开底部「API 设置」。 2. 填写对应平台的接口地址、API Key、默认模型。 3. 点「测试」,通过后自动打开「翻译可选」开关。 4. 启用后,该提供方会出现在右侧「翻译 API」下拉中。 - 支持:硅基流动、火山、LM Studio、Ollama、DeepSeek、智谱、Moonshot、OpenAI 等。 【第 7 步】开始转写 1. 点「开始转字幕」。 2. 可查看总进度 / 当前文件进度和运行日志。 3. 任务进行中,设置项会锁定,需等全部完成后才能更改。 【第 8 步】查看结果 - 字幕默认保存在音频同目录,文件名与音频一致。 - 若有失败,文件夹内会生成「失败记录.txt」。 - 若勾选了自动翻译,则会生成_en字幕或者_all字幕文件 四、两个模型的区别与选用建议 程序内置两个 opeai/Whisper 模型,路径均在 py/openai/ 下: 对比项 Whisper large v3 turbo(默认) Whisper large v3 ----------------------------------------------------------------------- 模型 ID openai/whisper-large-v3-turbo openai/whisper-large-v3 速度 更快,适合大批量 相对较慢 转写质量 优秀,日常听书/播客推荐 长音频时间轴更稳 Whisper 原生译英 不支持(无翻译训练) 支持 「自翻」选项 不可用 可用 「仅英文」选项 不可用 可用 推荐场景 只要原语言字幕、追求速度 要中英双轨或 Whisper 译英 【各自怎么用?】 场景 A:只要原语言字幕(最常见) 1. 选 Whisper large v3 turbo 2. 不勾选任何翻译选项 3. 开始转写 → 得到 文件名.srt 场景 B:要原语言 + 英文(Whisper 自己译) 1. 选 Whisper large v3 2. 勾选「自翻」 3. (可选)勾选「中英」或「英中」生成对照字幕 4. 得到: - 文件名.srt(原语言) - 文件名.en.srt(英文) - 文件名_all.srt(双语对照,若勾选了中英/英中) 场景 C:只要英文字幕(Whisper 译英) 1. 选 Whisper large v3 2. 勾选「仅英文」 3. 得到 文件名.srt(内容为英文) 场景 D:turbo 转写 + API 翻译任意语言 1. 选 Whisper large v3 turbo(或 large v3 均可) 2. 勾选「API翻译」 3. 选好翻译 API、源语种、目标语种 4. 得到: - 文件名.srt(原语言) - 文件名.en.srt(或 文件名.目标语种代码.srt) - 文件名_all.srt(若勾选中英/英中) 五、翻译选项说明 以下选项互斥,同时只能开一种主模式: 选项 作用 适用模型 ----------------------------------------------------------------------- API翻译 转写完成后,用 LLM API 翻译整份字幕 任意 中英 双语合并,源语种在上、译文在下 → *_all.srt 配合 API翻译 或 自翻 英中 双语合并,译文在上、源语种在下 → *_all.srt 同上 自翻 Whisper 先转写再译英,输出 .srt + .en.srt 仅 large v3 仅英文 Whisper 直接译英,只输出 .srt(英文) 仅 large v3 源语种:选「自动」时由 Whisper 检测;也可手动指定(如中文音频选 zh)。 六、输出文件一览 以音频「播客第1集.mp3」为例: 文件名.srt 主字幕(原语言,或「仅英文」时的英文字幕) 文件名.en.srt 英文字幕(自翻 / API 译英时) 文件名.zh.srt 等 API 翻译到其它语种时(扩展名为语种代码) 文件名_all.srt 双语对照(勾选中英/英中时) 失败记录.txt 批量任务中有失败项时生成 主角光环.txt 输入文件(可选,见下) 七、进阶功能 1. 主角光环(同音字纠错) 在音频文件夹内新建「主角光环.txt」,每行一个正确人名,例如: 张璐 李明 转写时会自动把同音错字替换为正确名字。 例如,某小说音频主角名称为张露 模型转写时可能会随机出现张禄,张璐,章录,脏路等等同音字 对于模型来说,这些都是对的,因此做了「主角光环.txt」 本程序会自动纠偏,最终输出结果时会输出报告  2. 设置自动保存 界面设置会写入 Sam.json(模型、文件夹、字幕参数、API 配置等), 下次启动自动恢复。 八、注意事项(重要) 1. 文件夹必须真实存在,且内含支持的音频文件。 2. 任务进行中不能切换模型、改路径或 API,需等待完成。 3. 仅扫描当前文件夹一层,子目录内音频不会被处理。 4. turbo 不支持 Whisper 自翻/仅英文;需要这些功能必须切换到 large v3。 5. API 翻译需先测试通过并开启「翻译可选」,否则下拉框无可用 API。 6. 授权与硬件绑定;更换主板/CPU/网卡可能导致授权失效,需重新申请。 7. 显存不足时可能报错或极慢;可关闭其它占 GPU 的程序后重试。 8. 如果事先知道音频时中文还是英文,应该在源语种选择好语种 9. 不限制音频时长,单音频16小时,5090 输出字幕时长约7分钟 链接: [https://pan.baidu.com/s/1eBMEm1nCUenbw6FYsst0nA?pwd=gpcb](https://pan.baidu.com/s/1eBMEm1nCUenbw6FYsst0nA?pwd=gpcb)
-
今天可以放假吗 我们今天可以放假吗? 所以,我们似乎正处于全球白领劳动力(以及很大一部分美国劳动力)生产力革命的开端。 人工智能将彻底改变我们的工作方式、与世界互动的方式、学习方式、社交方式等等。 这听起来很棒。 的确如此。 一切都变得更快更便捷,对我们所有人来说都将是莫大的福音。 那我们能放一天假吗? 如果人工智能能够使我们的生产力全面提高 10 倍, 那就意味着我应该能够在周一中午之前完成以前需要一整周才能完成的工作量。 那我周五可以休息吗? 从现在开始,我周一、周二、周三、周四上班,周五休息。 我们甚至可以把周五定为“AI员工日”; 我保证周四会拼命写出高质量的题目,然后周五经纪人就可以全天使用这些题目了。 这样一来,你们周五也几乎没损失什么时间,对吧? 当然,这适用于所有人。 所以,各位董事会成员和高管们,你们周五可以休假去高尔夫球场打满18洞。 想想都觉得美妙,不是吗? 你们不用待在办公室,因为我也不在。 你们不用待在办公室,因为人工智能代理在那里。 我也不用! 仅仅多一天而已。 考虑到人类生产力各个领域发生的巨大变革,这似乎合情合理,而且确实只是一个很小的改变。 (嘿,埃隆:我正在努力提高生育率。 在加州,三个小孩的托儿费一个月要六千美元。 我这周必须五天都去办公室吗? 为什么不去四天?) 文章提出一个问题:AI 大大提高了白领工作的效率,以前一周的工作,现在几个小时就能完成,那么可以放假一天吗? 这个建议完全是合理的逻辑。 既然更少的时间完成了同样的工作,那么放假对公司并没有损失。 反而,要是不放假,也不加薪,那么 AI 对员工的意义是什么? 除了员工因为 AI 有了更多的工作技能和成果,我认为,一个可能的答案是: AI 提高了全社会的生产效率,这意味着长期中,所有工作岗位的 平均薪资(或福利) 是提高的。 本文转载 [https://mlsu.io/posts/day-off/](https://mlsu.io/posts/day-off/) 
-
基于FLUX.2-klein_二创的_人像修饰工具_AI修图 基于FLUX.2-klein 二创的 人像修饰工具 ### **仅适用于单人人像修饰,对大头贴效果比较好** 限于当前模型,目前无法做多人的,例如两人的,以及合影的,等等,这些不是软件问题,是模型问题,这个解决不了 不限制最高像素,4000w像素输入,4000w像素输出,峰值需要12gb显存 低于1024分辨率的,自动补齐1024 有单张模式,也有批量模式 33元离线授权 后续如有新版升级免费 供72小时无限制全功能试用 该项目需要12gb显存,4060 tis 16gb显卡,约60秒一张,5090 32gb显卡14秒一张,3000x4500像素的 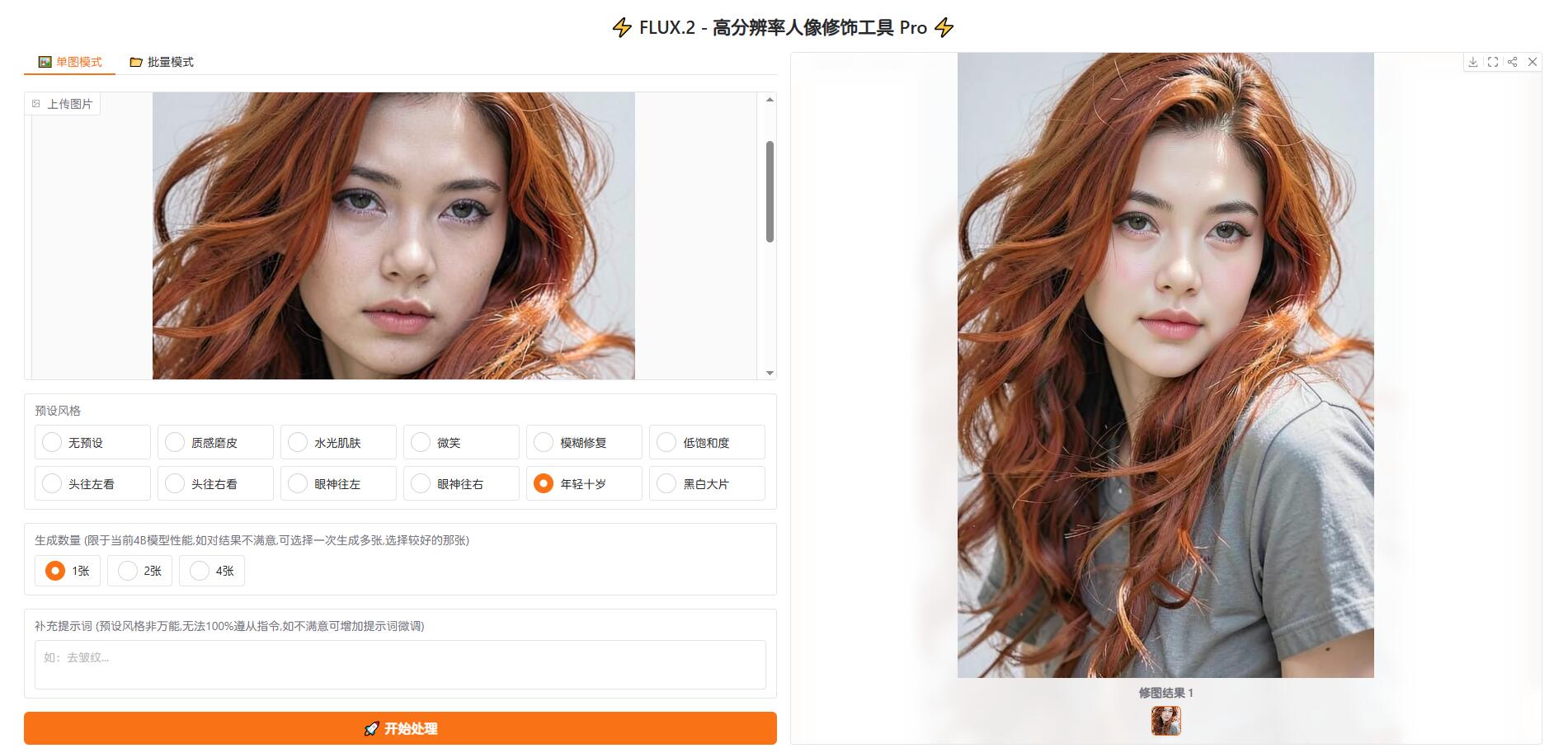 2.0版 https://pan.baidu.com/s/18iM2sfSHhC3h9O6N3ZANdw?pwd=gpcb
-
基于FLUX.2-klein-base-4b二创的键盘摄影大师-V5 基于FLUX.2-klein-base-4b二创的键盘摄影大师-V5 源自jian27 [https://www.jian27.com/html/2573.html](https://www.jian27.com/html/2573.html) 5.1 增加去掉反光功能,不能100%去除反光,这个应该有常识 5.2 修复输出图片变形问题 5.3 增加载入右图到输入框,让生成的图片作为底图重新编辑,例如去除文字后,再编辑图片等等场景 5.4 修复单张出图无法载入问题,修复载入图片是之前的旧图问题 5.5 修复页面遮挡问题,1080 27寸显示器,按钮被遮挡一部分,已修正 本工具模型为4B版本,需要12gb显存运行,最低要求3060 12gb版本,或4060 16gb版本等等 内置53种常用预设,你不会找到其他版本有这么多预设了,全部精挑细选,从一百多中预设中只保留这些效果最好的 由于模型原因,有时候并不能生成满意的照片 相同的照片,每个预设都生成一次,也有根本没效果的 这个就是俗称的抽卡,有时候效果非常好,有时候几乎没效果还更差 这个模型是4B参数的,不要与那些各家在线模型相比,天壤之别,在线模型可以达到1000B参数 目前来说,有这个效果,我个人已经非常非常满意了 出图首选尺寸依然1024 超过这个尺寸,可能多手多脚,这个不解释,懂的都懂 5090 文生图3秒,图片编辑 7秒 均为1024短边边长 可以生成1600*1600分辨率图片,效果一般 小于12gb显存的,不用下载,无法运行!!!!!!!!!!!!!!内存16gb或以上就行 提供试用版,需要联网验证,自动验证的,联网即可 验证后提供72小时试用许可,试用期间不限制张数,全功能试用 99元收费后提供断网离线验证许可,离线版不限制时间 左右扩展,上下扩展,四周扩展,这几个并不是总会生效,很多时候没有效果 999提供源码(不含验证机制的源码) 版面排版极度舒适,十分适合强迫症患者服用 以下为新版截图 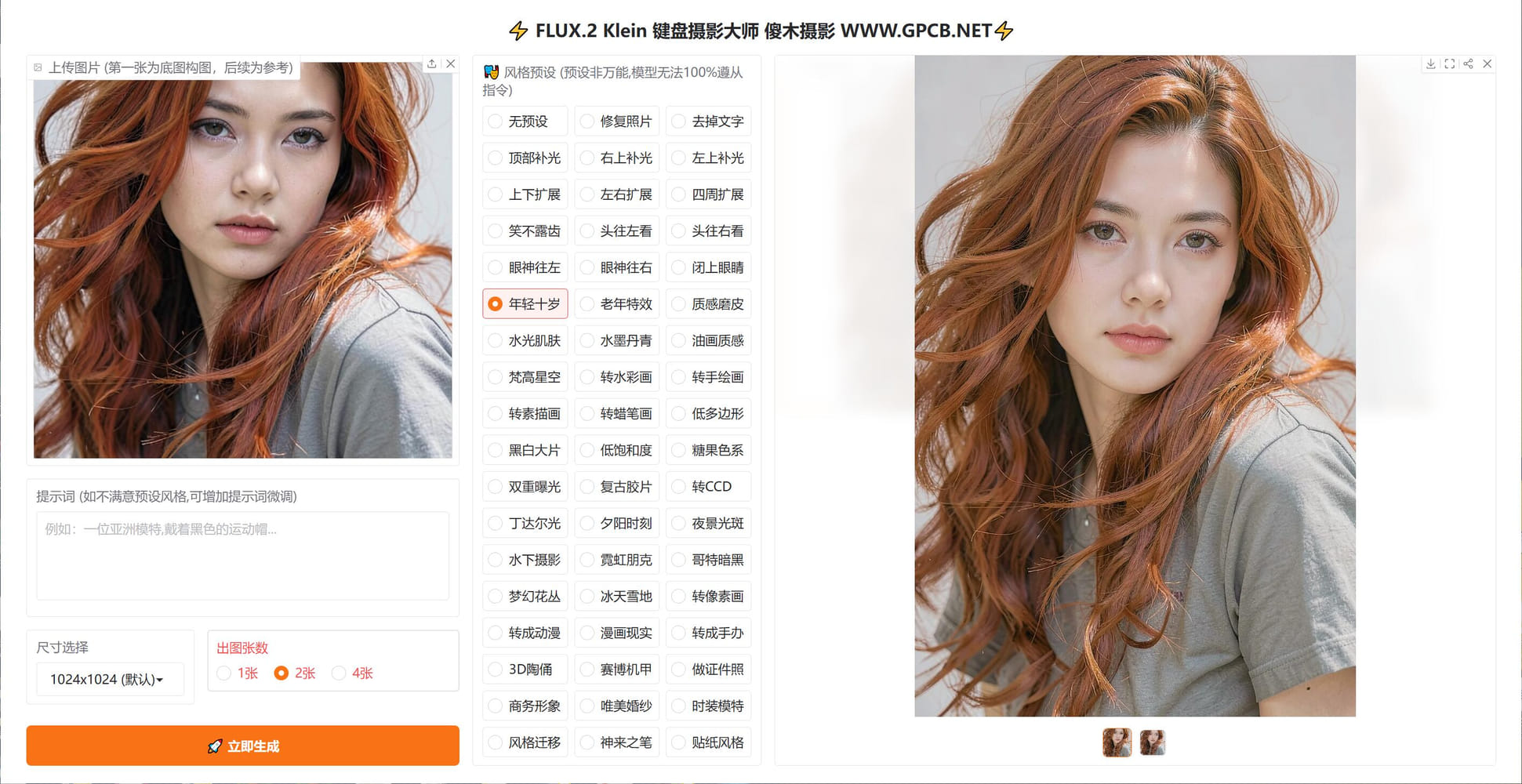 以下功能均包含,以下界面是旧版的,新版均有相应增强 超强去水印 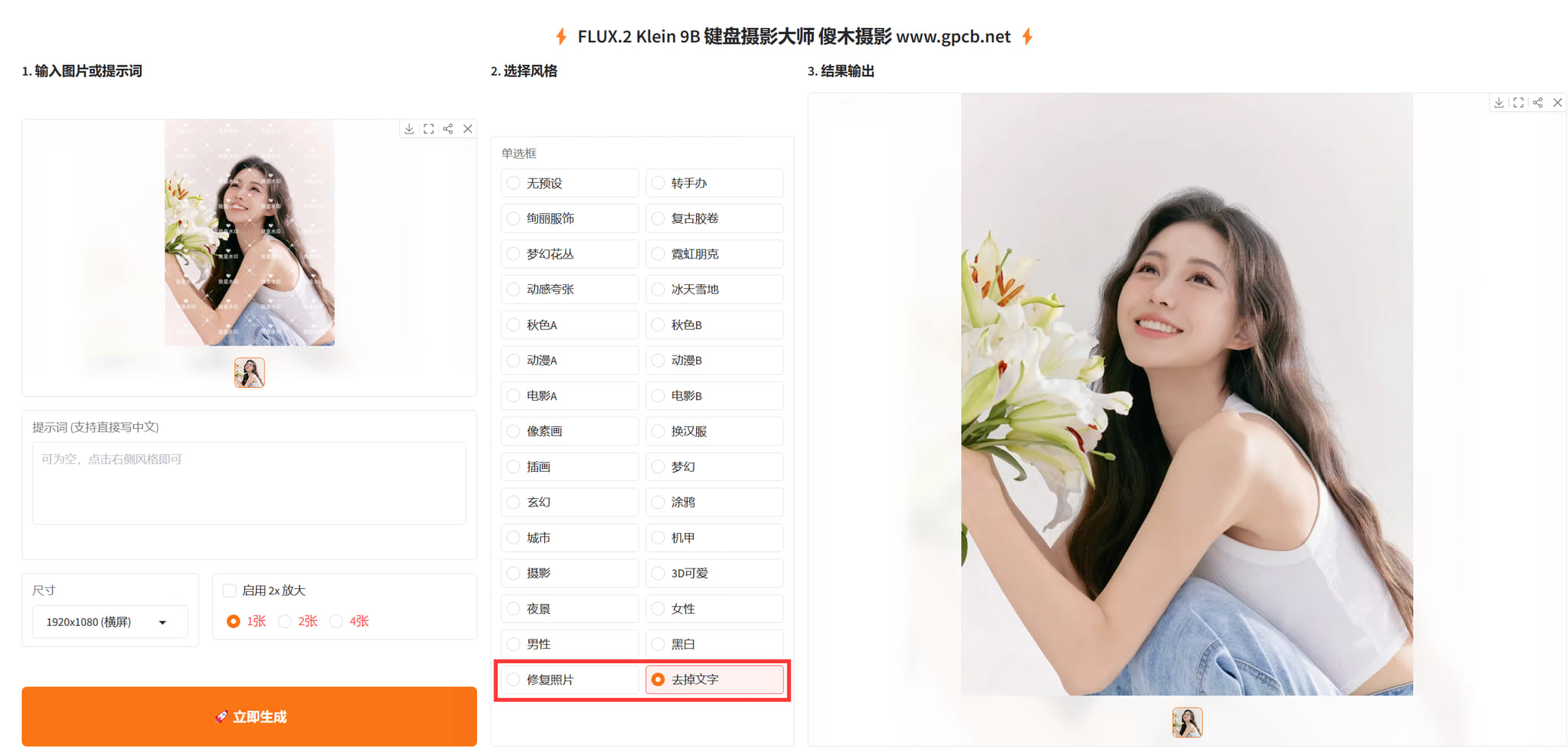 老照片修复(不限于老照片,大头贴之类的,都可以修复,可以高清还原) 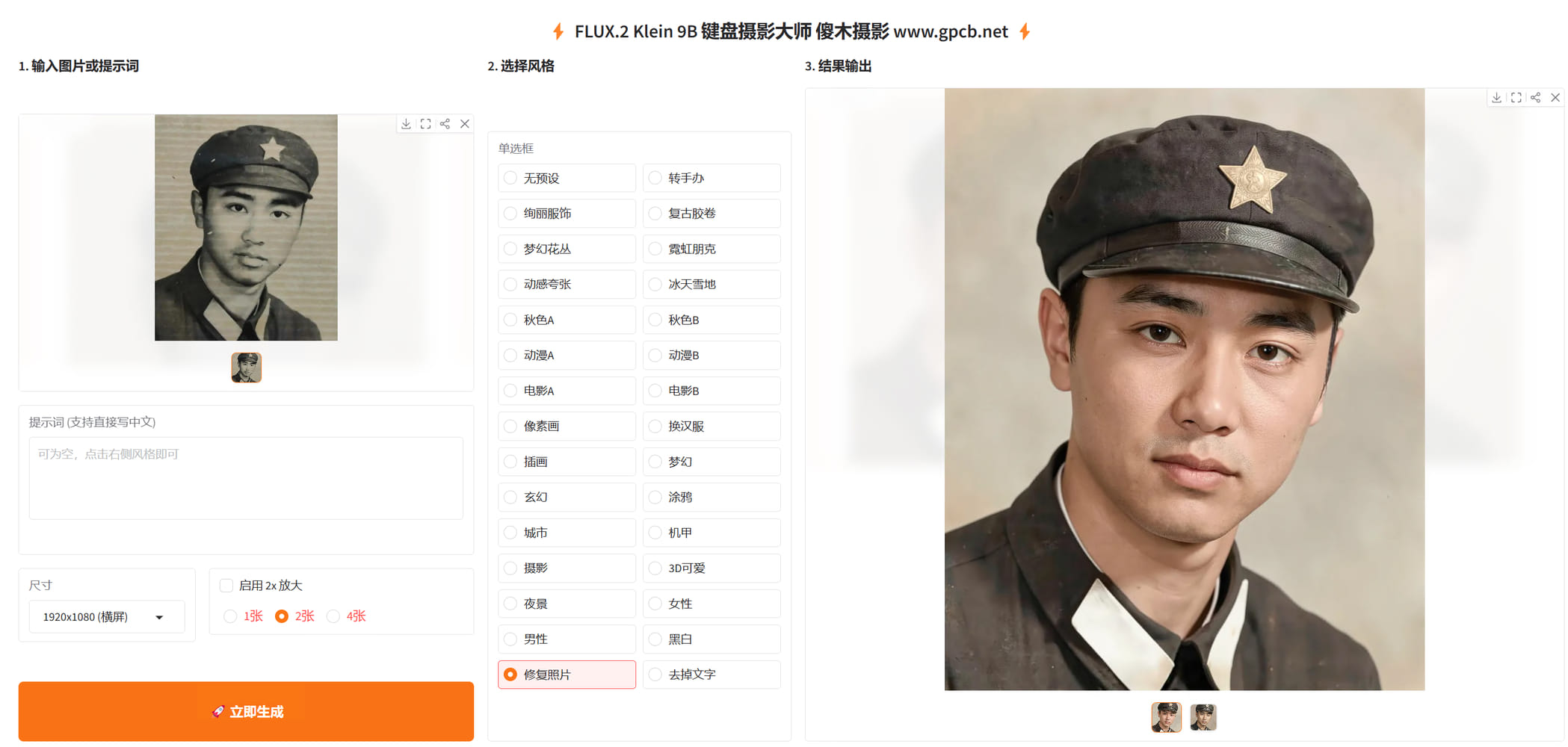 漫画,线稿,转真人 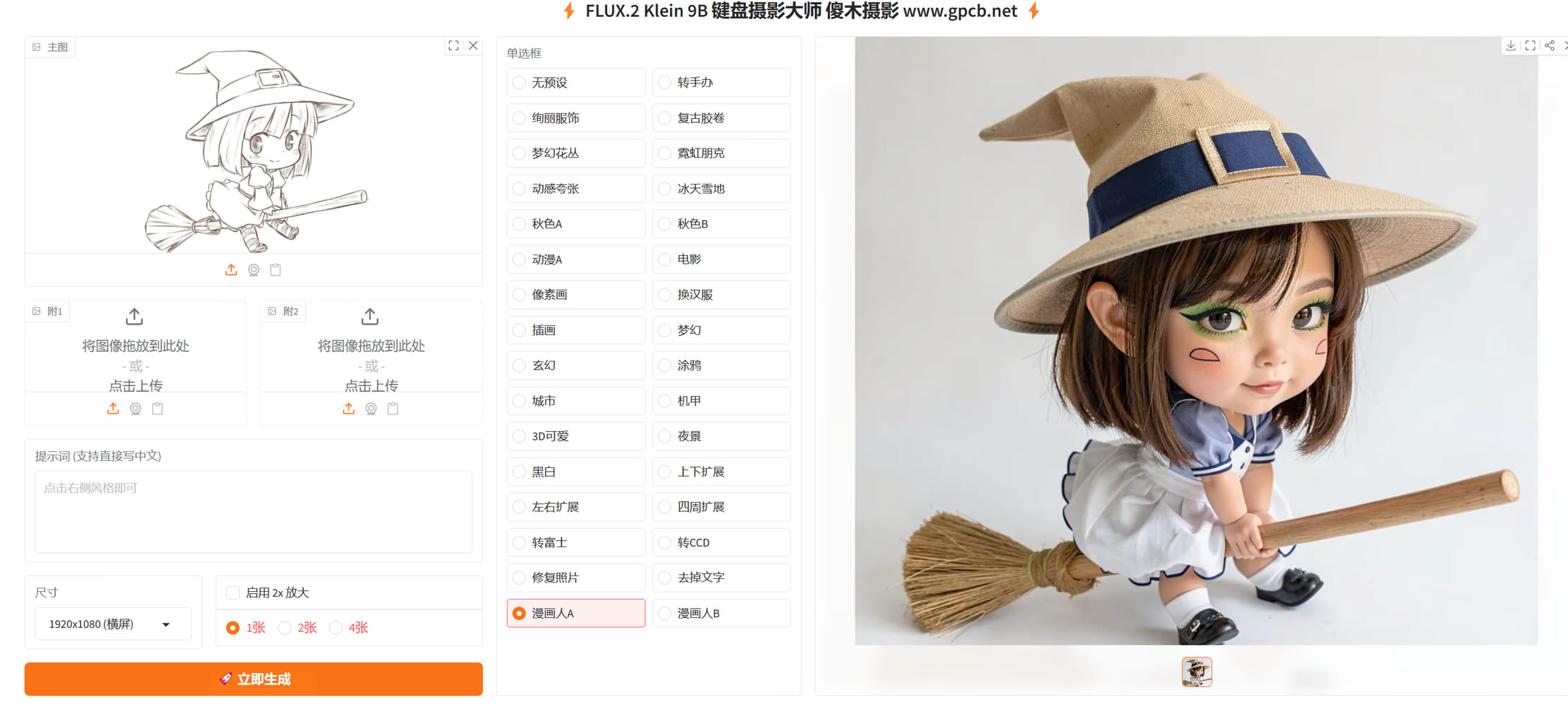 链接: [https://pan.baidu.com/s/19awjTvDpGvhpjdaw8Rzd7Q?pwd=gpcb](https://pan.baidu.com/s/19awjTvDpGvhpjdaw8Rzd7Q?pwd=gpcb)
-
最好用的智能便签系统 最好用的智能便签系统  就一个便签,为什么叫系统? 因为这是可以团队协作的 我们部署在云端,只要有网络的地方,都可以使用 且已与企业微信集成 打开企业微信就可以直接使用 便签可以单向分享给任意注册用户,但是接收者不允许分享给第三方等等 数据记录在数据库中 因此,叫做便签系统毫无问题 由于慢慢改成了牛马系统 为回归本质,已增加图钉功能 相当于免打搅模式 点亮图钉后,启用置顶功能 优先于所有排序规则 例如新建的标签不会跑到最前面,任何情况下,点亮图钉的,都会在最前面 如果有多个便签点亮了图钉,则这些便签你可以手动调整位置排序 有完善的用户管理,有便签删除恢复,有离职便签移交  已开放注册使用,请注意不要保存重要资料,不要保存各种账号密码等等!!!!! 仅供测试 本系统对外出售,可以离线部署,需要 php > 7.0 遇到密码遗忘的,可以发送账号信息到 abpyu@139.com 邮箱 [https://gpcb.net/b/](https://gpcb.net/b/)  已增加AI功能,可以帮你快速分析任务轻重缓急,并给出合理规划建议 目前使用的阿里 qwen3-max 模型 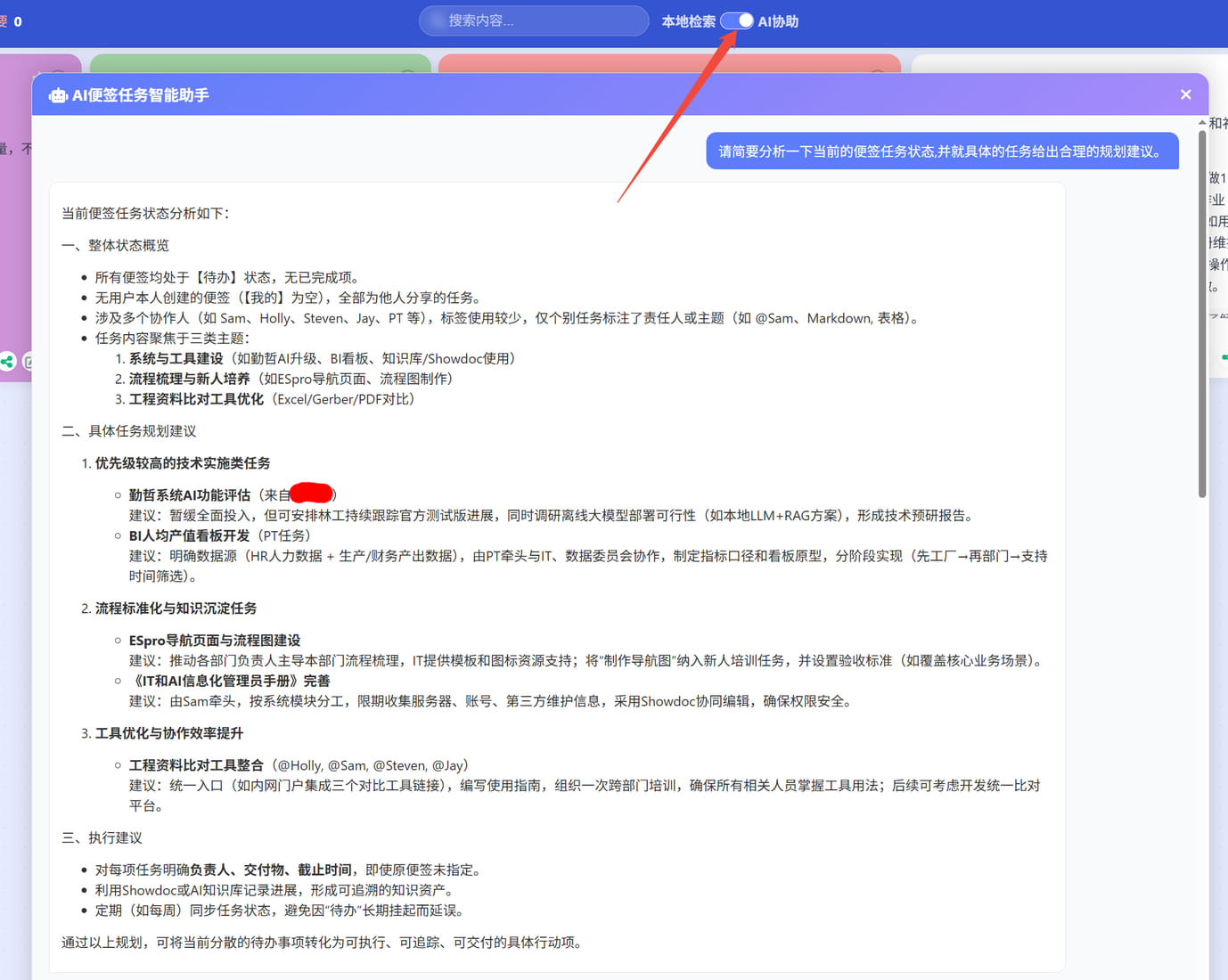
-
Z-Image-Turbo 负优化版 Z-Image-Turbo AI生图大模型 高性能AI图像生成工具 11秒一张图片 本站负优化版 主要针对18gb以上的显卡进行了优化,常驻显存17gb以上,内存占用约10gb左右 因此仅供显存富裕的用户使用 显存不足的,请到以下链接下载jian27版本 本项目来源于: [https://www.jian27.com/html/1779.html](https://www.jian27.com/html/1779.html) 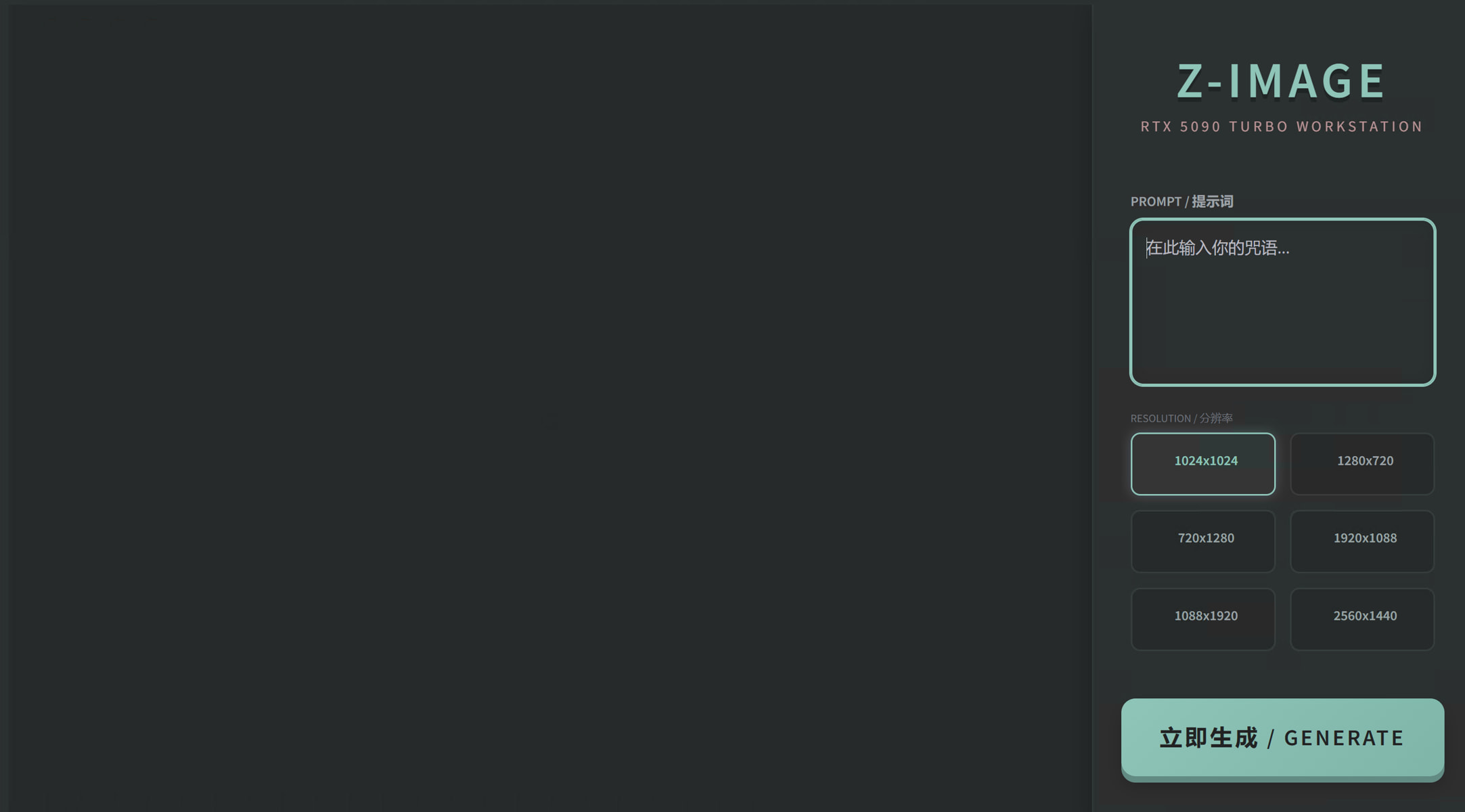 该模型依然使用的1024分辨率进行训练,因此最佳分辨率依然是1024 但是生成的人像具有非常不错的质感,与其他模型生成的硅胶皮肤大为不同 链接: [https://pan.baidu.com/s/17yNCwAk0BASxd-U_IuC9Ow?pwd=gpcb](https://pan.baidu.com/s/17yNCwAk0BASxd-U_IuC9Ow?pwd=gpcb)







网站版权本人所有,你要有本事,盗版不究。 sam@gpcb.net