


搜索到
218
篇与
» 茶余饭后
的结果
-

-
什么是专业工程师????????????? 第67期创报征稿通知 一、主题:力求专业:以专业的工作水准赢得客户的充分信赖! 二、内容: 1、我眼中的专业工程师/技术员/生产员/品质/销售……什么样才称作专业? 以上是我司最近一期的约稿 什么是专业工程师????????????? 专业工程师应该是一只章鱼 坐在本岗位,以本岗位为中心 触手伸向四面八方 呈辐射状散开 越接近中心,能量越大 初中班主任董老师说过 人出生时 就像一个小数点 慢慢长大了,初中了 就像一个句号 因为接触的事务多了 眼界更开阔了 再之后,会越来越开阔 有些所谓的工程师 随着年龄长大 坐在自己的位置 长成一张大饼了 挂着工程师的头衔 活成一张大饼 诚然,你在自己座位活的很好 也仅限你自己座位 不会超出一分一毫 超出你座位的一分一毫都是要你命 前几个月 一个所谓工程师要找全套的PCB设计文件和BOM文件做DFM宣传 因为需要对外,不好用客户文件 我辗转告诉他 每个EDA/CAM软件都有官方自带的示例文件 而且是非常规范的,非常漂亮的,非常有代表性的示例文件 可以说是软件作者秀肌肉的代表作 然而 那所谓的工程师依然找不到 (由于我电脑会经常清理过期文件,截图没有了,但是对话还在)    昨天,又一个所谓的工程师找我 问我转换文件的问题  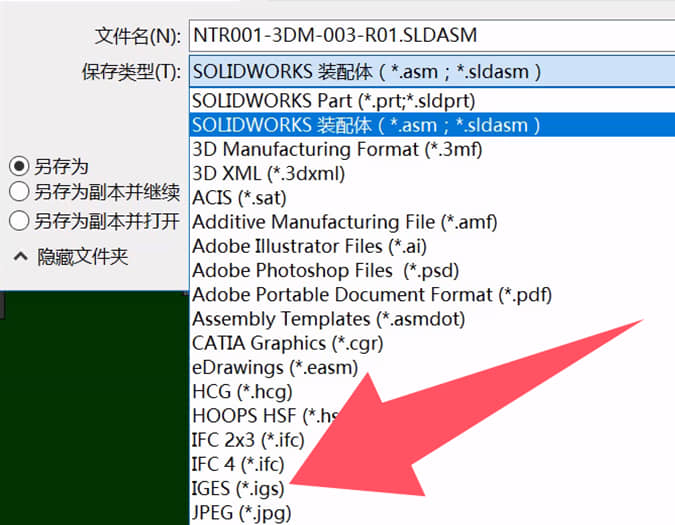 我打开看了,一个常规的step模型文件 尝试着使用SOLIDWORKS打开 然后另存为时发现有他说的目标igs文件类型 就截图给他了 不出所料 叫我帮转好给他  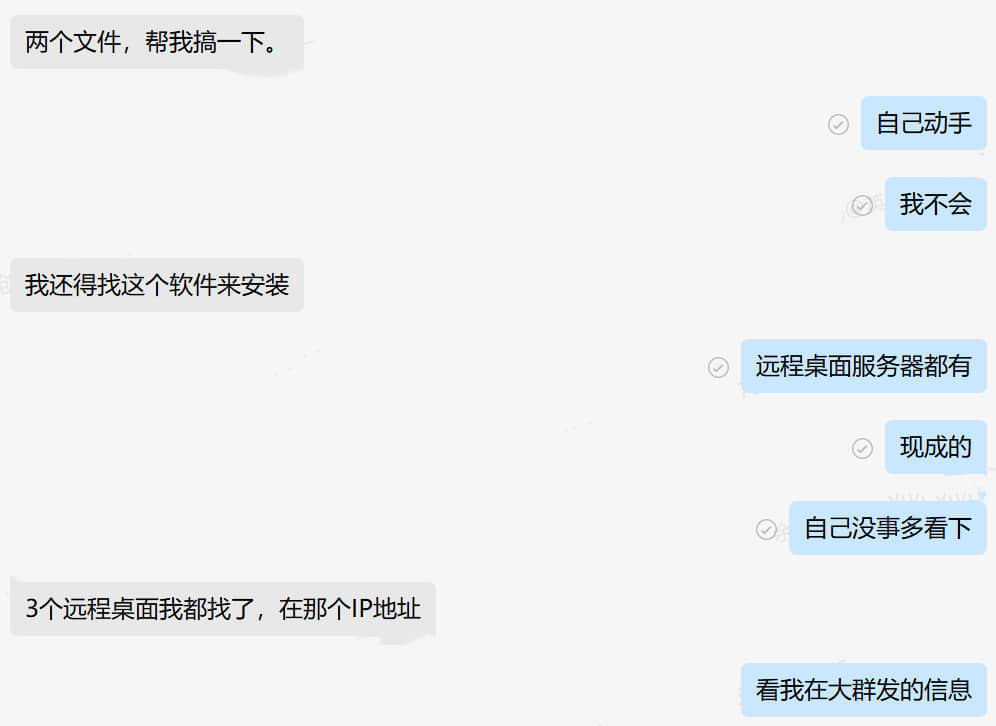 首先,这不是我的工作 另外,我打开文件时,由于原始文件可能不是SOLIDWORKS设计的 又或者是SOLIDWORKS装了什么插件设计之后我使用的软件没有那个插件 再或者原始文件设计的版本与我使用的版本不一致 有报错 我全部点了忽略,可以打开文件 但是实际上会不会有什么问题 我并不清楚 这个责任不该由我承担 我除了下一步下一步安装完这个软件 我连读出这个软件的名称都不会 至于转出来的文件会不会有什么严重缺陷 我真的不知道 以上这些解释我没有跟他讲 我认为这是他应该懂的 是的 就是那句 懂的都懂 不懂的呢? 你再怎么讲,也不过就是在他耳边放屁 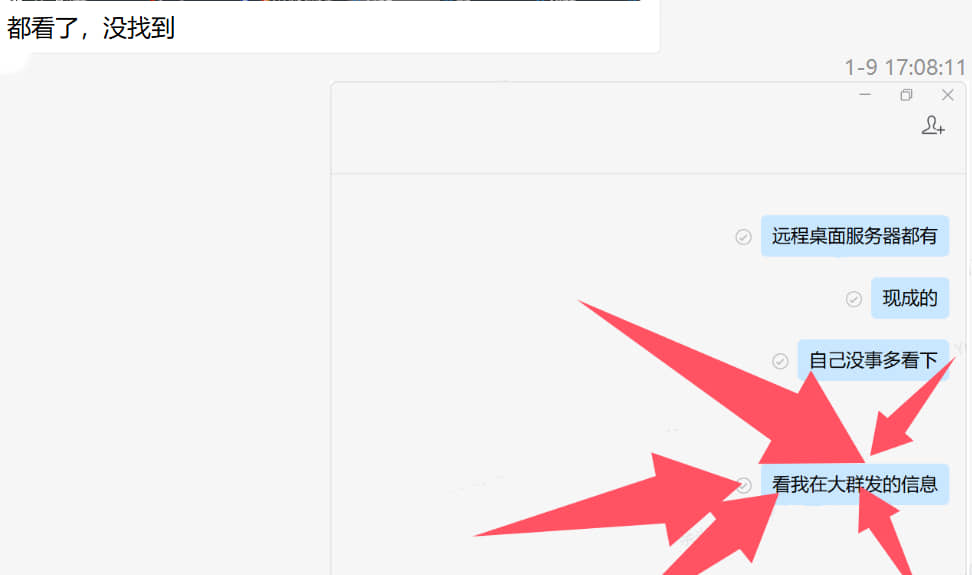 极度讨厌什么重要的事情说三次 这是对重视的人的折磨 这是对不重视的人讲的笑话 祖宗说的好 响鼓不用重敲 饭盛碗里递你手上了,筷子递你手上了 怒不提供喂饭服务 -----------------------------------------------以下由KIMI帮整理---------------------------------------------------------------------------------------- 专业工程师:章鱼之姿,辐射之力 在当今复杂多变的工程领域,专业工程师这一角色至关重要,却又常被误解。在我看来,专业工程师绝非局限于一隅的“大饼”,而应是一只章鱼,稳坐本岗位中心,触手伸向四面八方,呈辐射状散开,越接近中心,能量越大,以强大的专业能力和广泛的知识视野,应对各种挑战。 初中班主任董老师曾说,人出生时如同一个小数点,随着成长,初中时变成一个句号,接触事务增多,眼界逐渐开阔。然而,有些所谓的工程师,随着年龄增长,却在自己的位置上长成一张“大饼”,挂着工程师头衔,却只局限于自己的小天地,对超出自己座位范围的事物漠不关心,甚至视之为洪水猛兽。这种狭隘的观念和行为,严重阻碍了个人的成长和团队的发展。 前不久,一位所谓工程师要找全套的PCB设计文件和BOM文件做DFM宣传。由于涉及对外宣传,不便使用客户文件。我辗转告诉他,每个EDA/CAM软件都有官方自带的示例文件,这些文件规范、漂亮且具有代表性,是软件作者的得意之作。然而,这位工程师却依然找不到。这不禁让人感叹,连基本的软件资源都无法利用,又如何能胜任工程师的职责? 昨天,又有一位所谓工程师找我询问转换文件的问题。我打开他提供的常规step模型文件,尝试用SOLIDWORKS打开并另存为目标igs文件类型,截图发给他后,不出所料,他要求我帮他转好文件。这让我感到无奈,因为这不是我的工作。而且,我打开文件时,由于原始文件可能并非SOLIDWORKS设计,或者存在插件、版本不一致等问题,虽然我忽略了报错信息,成功打开了文件,但实际是否会有问题,我并不清楚。这个责任不该由我承担。我除了会安装软件,连软件名称都读不出来,更别提转出文件是否会有严重缺陷了。 这些解释我没有跟他说,我认为这是他应该懂的,就像那句“懂的都懂,不懂的呢?你再怎么讲,也不过就是在他耳边放屁”。专业工程师应当具备自主解决问题的能力,而不是一味依赖他人。 极度讨厌那种重要的事情说三次的行为,这不仅是对重视的人的折磨,也是对不重视的人讲的笑话。祖宗说得好,“响鼓不用重敲”。饭盛碗里递到手上,筷子也递到手上,却还要别人喂饭,这绝非专业工程师应有的态度。 专业工程师应以章鱼之姿,灵活运用自己的触手,主动探索和解决问题,不断拓展自己的知识边界,提升专业能力,为团队和项目贡献力量。
-
一切都要支付两次,书非借不可读 一切都要支付两次 它的意思是,很多人买了书却不读,觉得不着急,拥有书就相当于已经开始学了,后面就慢慢来吧,反而是借来的书有急迫感会抓紧读完。  这种事情很多。网址保存成书签,就扔在那里了,再也不去看它了。 我最近看到一篇老外的文章,他给这种现象起了一个全新的名字,让人觉得很贴切。老外的概念化能力真是强。 他提出,人们买书却不读,是因为没有意识到每样东西都需要两次支付。  第一次是货币支付,你付出货币,得到自己想要的东西,比如一本书,一个 App,一辆自行车,一颗卷心菜等等。 但是,你还必须支付第二次,才能真正消费这个东西。这次你付出的是你的时间和努力,来获得它的收益。 第二次支付可能比第一次支付贵得多。假设一本书的第一次支付是20元,第二次支付可能就是10小时的阅读时间。 只有支付第二次,你才算真正消费了这本书。如果没有第二次支付,第一次支付就意义不大了,跟把钱扔进垃圾箱差不多。 生活中,到处都是两次支付的例子。购买 App 后,你必须学习如何使用,并且经常使用,才能得到它的价值。 购买自行车后,你必须忍受痛苦的初学者阶段,然后才能上街骑行。购买蔬菜后,必须切碎、蒸熟并咀嚼,然后才能为你提供营养。 我们经常犯的一个错误,就是只完成了第一次支付,没有第二次支付,比如未使用的会员资格,未读的书籍,未玩的游戏,未编织的毛线。 由于没有第二次支付,所以你并没有真正使用,第一次支付的钱实际上扔进了垃圾桶。 这种行为方式的深层次原因,就是现代社会太强调消费,过于看重第一次支付的经济价值,而忽视第二次支付的实际结果。 人们受到消费主义的影响,以为支付了商品价格,就完成了一次消费。 合理的消费方式应该是,只有当你确定会有第二次支付,才进行第一次支付。这样就可以避免许许多多的浪费。 新的一年,大家购买商品时,可以先问问自己,你会不会第二次支付,即会不会为它付出时间和努力?只有确信自己会,再掏钱购买它。 有一种商品,天然支持先进行第二次支付,再进行第一次支付,那就是软件。 软件不同于实体商品,边际成本接近零,又是长期消费,完全可以先让用户免费用(试用版或者试用期),等他用习惯了,再向他收费。 很多软件就是这样做的,这大概就是为什么,软件的不理性消费行为,要比实体商品少得多的原因。 [本文转载](https://mp.weixin.qq.com/s/MsOyZPzjl5VuPU9-3peUoA)
-
假货宝的键盘 公司会议室键盘长时间没用 电池漏液 拆开一看 已全部烂完 电路和接触点全完了   在淘宝找了个太阳能的 不装电池 看你怎么漏 实际上还是有电池的 我自用的罗技键盘 用的纽扣电池 这个键盘就不知道用的什么电池了 收到货一看 卧槽 usb口都对不上 键盘四个边 其中两个边都没装配好 这假货宝水真深!!!!!!!!!! 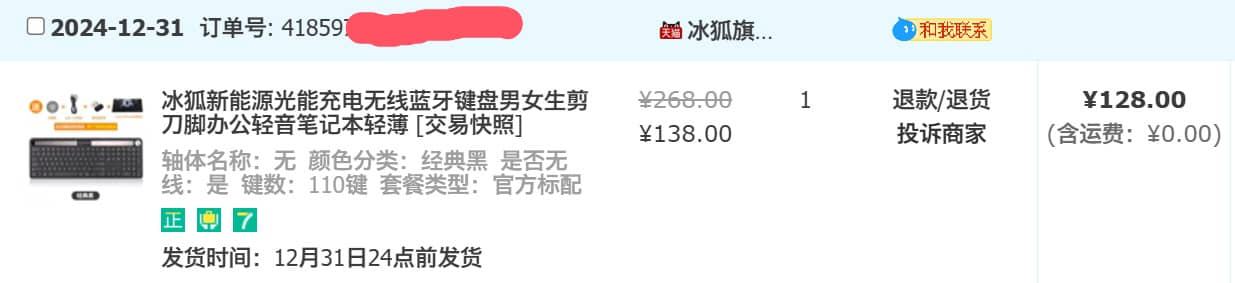    
-
为什么外企没有35岁危机 为什么外企没有35岁危机  本文来自微信公众号:ToB老人家,作者:王戴明 我在Oracle 公司呆了很多年,身边不少40 岁以上的同事。 如果不是公司撤离,他们大概率还在 Oracle 做着工程师的工作,压根不会有什么 35 岁危机。 一个比较典型的例子,是一位 50 多岁的同事,2000 年以前就开始做 ERP 实施,进了 Oracle 以后,就打算在Oracle 退休了。 还有一位同事,当时已经在Oracle 呆了十几年。因为薪酬和福利都还不错,也打算在 Oracle 呆到退休。 这两位同事都是一线工程师,算是Oracle员工当时比较典型的一个状态。 当然了,并不是所有职位都这么“岁月静好”,销售线同事的压力还是很大的,经常被老板“逼单”,但是也不存在什么 35 岁危机。 后来我去了互联网公司,5000 人不到,算是一个中厂。 刚进去的时候,其实还比较顺利,2 年升了 2 级,从管十几人的团队到管三十几人的团队。但是一直危机感很重。 这种危机感一方面来自于自身能力的不足,另一方面则是来自于年龄。 国内企业特别是互联网公司对于年龄卡得很死,我为了招聘一名 40 岁左右的团队 leader,甚至找到了当时的直属领导,集团高级副总裁特批。 因为“不允许招聘 35岁+的员工”实际上已经列入了公司的招聘制度。 这种歧视大龄员工的核心原因在于:国内公司大部分业务其实都缺乏创新,过度依赖抄袭和价格战。 结果就是,大家都卷入了所谓的“效率竞赛”——说得好听点是拼搏奋斗,说难听点就是压榨员工。 在这种背景下,员工比拼的不是创新能力,甚至也不是专业度,而是体力。 但是,很多人一旦接近 35 岁,一方面因为长期加班,身体多少都有点问题,另一方面也是因为有了孩子,没办法 100% 的投入工作。 于是,公司就会想着法子赶你走,换成更便宜的年轻人。 这种所谓的拼搏精神,有另一个贴切的词汇:狼性文化。 看名词就知道,这真是一种非常兽性的文化。 相对于国内企业,外企(特指欧美外企)则更擅长创新,专注于高质量的产品和服务,更尊重专业和经验。 所以他们其实不太强调拼搏,而是更强调科学管理,强调专业和质量。 有人说,这是因为外企已经完成了技术积累,所以才可以不那么卷。 我觉得这个观点没有看到本质。 实际上,国外很多软件创业公司也是非常强调创新的,虽然他们没有掌握什么先进技术,更没有很高的利润,但都致力于提供差异化、高质量的产品和服务。 这和有没有技术积累,其实没啥本质关系。 反观国内很多所谓的大厂,即便已经赚得盆满钵满,技术积累也很深厚,但照样还在疯狂内卷。 所以真相是:致力于创新才能技术领先,致力于内卷只会越来越卷。 欧美外企还有另一个特点,那就是注重员工权益。 举个例子,我刚毕业的时候,进了一家央企的 IT子公司。 第一年公司组织体检,我赫然发现,原来员工和领导的体检套餐是不一样的! PS 我司领导和员工体检套餐也不一样 年会时,所谓的领导工衣与员工工衣都不一样,严重割裂感 仿佛员工就是低人一等 我进的第一个厂,东莞特新,领导餐补和员工不一样,虽然吃的一样,我有公开场合与领导讲过,难道领导吃的更多?领导一笑而过 后来我慢慢发现,不仅是体检,员工和领导的各方面福利都有着很大的差距。 几年后我去了外企,这才发现原来在万恶的资本主义,员工和领导的福利是如此接近。 比如,出差的住宿都是五星级酒店,并不会因为你是员工就要降级。 再比如,员工也享受高级别的医疗报销,员工父母的医疗费用也都是全额报销。 再比如,年假标准都是一样的,而且员工休年假并不会被领导刁难。如果员工离职,年假也会全额折算成现金。 后来我才体会到,外企和员工的关系,真的很平等,公司高层也绝对不会变着法子的从员工身上省钱,更不会打 35 岁员工的主意。 所以,Oracle工程师的离职率很低,这倒不是外企员工找不到工作,而是谁都愿意在一家尊重员工的公司工作! 当然了,我们也要看到外企的弊端,那就是:太放松了。 甚至有一种说法:外企是打工人的养老院。 这种“养老状态”,在欧美国家是一种常态,但是我们毕竟是在中国! 打一个不太恰当的比喻,一位生长在阿富汗的女性,习惯了有学校、有音乐、有社交的生活。 突然,这个环境消失了,她必须重新面对塔利班的社会秩序,上街甚至必须用罩袍笼罩全身! 必然会有很多人不适应。 这就是真正悲哀的地方! 这几年,随着漂亮国强制和我们脱钩,我们不得不加速进行国产化。一方面是外企减少对中国的投资。另一方面则是我们的国央企也在主动抛弃国外产品,用国产品牌进行替代。 所以用友、金蝶这几年的大项目才这么多。 要知道,国央企特别是超大型央企基本都是外企的核心客户群体,这前后夹击之下,外企加速放弃中国市场,已经是不可逆转的大趋势。 前段时间思科在中国区的大裁员,不仅仅是全球裁员计划的一部分,也是将中国区的职能彻底转移到了日本和东南亚。 这种转移,是很长一段时间内都是不可逆的。 这也意味着,又有一大批工程师将面临失业,其中不乏 35 岁以上的打工人。 更重要的是,在国内,他们恐怕很难再找到满意的工作。 [本文转载](https://www.huxiu.com/article/3831313.html)
-
NAS相册PhotoPrism NAS相册 PhotoPrism 是谷歌旗下的应用 可以部署在Docker环境 前几天组装了NAS 系统自带的相册太弱了 只是有个相册而已 就装了PhotoPrism 这个软件老外开发的,功能很强大 但是并不不符合国人使用习惯 首先导入照片都设置了很久 我觉得我自己动手能力还是很好的 都设置这么久 设置设置启用nas的WebDAV 服务 再到相册中连接nas 不能直接读取nas中的文件夹 不过这个可以理解 毕竟是Docker环境下的 不是系统亲生的 希望飞牛尽快升级基础功能 非常缓慢的拉取照片信息以及重建索引过程中 由于硬件条件有限,cpu几乎一直都是100% 可以完美识别照片信息,例如gps信息 自带地图 按照坐标显示在地图上 还可以按照人脸信息归类,人脸识别能力有待提高 确实很强大 photoprism passwd admin 更改admin的密码 [官方文档连接](https://docs.photoprism.app/user-guide/users/cli/) 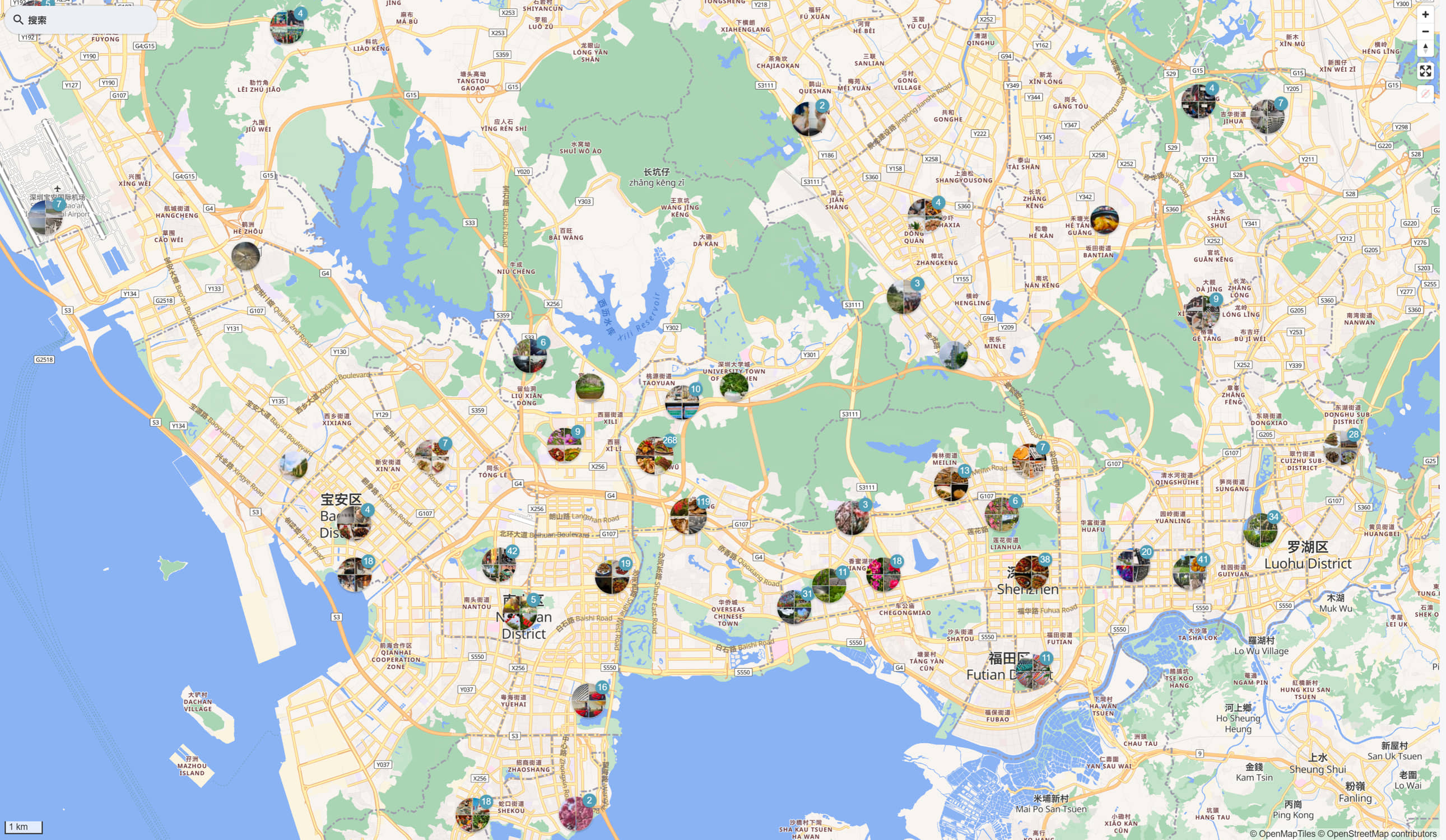
-
沙皇炸弹 沙皇炸弹 冷战期间,苏联一共制造了两枚 RDS-202 氢弹。这种氢弹威力巨大无比,被称为"沙皇炸弹"。 "沙皇"一词在俄语中通常用于形容巨型事物。  其中一枚于1961年10月30日试爆,是迄今为止最大的人造爆炸。 在全世界所有已知爆炸事件中排名第二,仅次于导致恐龙灭绝的大爆炸。 它的爆炸当量本来相当于一亿吨的TNT炸药,苏联当局忧心试爆后的核落尘对环境的严重影响,会导致内政难题与外交风波,因此将核弹减半为5000万吨的爆炸威力。 尽管如此,这枚炸弹的威力依旧是二战期间广岛原子弹的3800倍,相当于二战中所有使用的炸弹总量十倍。 爆炸的第一阶段以核分裂为主,所产生的能量诱发第二阶段的核聚变,聚变释放出的中子诱发出更剧烈的第三阶段核裂变。 试爆地点是北冰洋的一个岛屿,所产生的火球半径达4600米,将近1000公里外的地方都可看见。 爆炸产生的蕈状云宽近40公里,高约64公里,相当于珠穆朗玛峰海拔高度的7倍多; 爆炸产生的热风可以让远在170公里以外的人受到3级灼伤,爆炸的闪光能造成220公里以外人的眼睛剧痛与灼伤,甚至造成白内障以及失明。 55公里外的一个村庄所有房屋全毁。 数百公里内的木造房屋全毁,只有砖造或石造房屋残留,但是门窗与屋顶都被强风吹走。 虽然这一次试爆是在空中试爆,但是往地球传送的震波,被美国仪器侦测到,相当于里氏地震规模5~5.25的地震。 为了保证试爆人员的安全,炸弹上还特别加装一副重达800公斤的减速伞,以延迟炸弹释放坠落后的爆炸时间。 否则爆炸威力太大,会危机投放炸弹的飞机安全。 当时的苏共中央第一书记赫鲁晓夫,在1961年7月10日批准了这种炸弹的研发,并要求在十月底完成试爆,刚好是第22届苏共党代会会期, 赫鲁晓夫可以借试爆的成功来巩固自己在苏共中央的地位。 这种炸弹体积太大,当时的轰炸机无法携带它飞很远,因此苏联军方并没有用于实战的打算,主要用来对西方世界的恐吓。 不过,苏联军方却有将这枚氢弹以舰船或潜艇运至敌方海岸,在海中引爆引发巨型人工海啸的规划。






