


搜索到
36
篇与
» AI
的结果
-
 nstantIR,AI图像修复 nstantIR 是一个在 GitHub 上的开源项目 InstantIR 采用了深度学习技术。通过使用深度神经网络,InstantIR 学习图像的特征,从而更好地理解图像的内容。 用于图像的相似度计算,实现快速准确的还原修复受损的图片。 jian27打包 [https://www.jian27.com/html/2418.html](https://www.jian27.com/html/2418.html) 本站二次负优化 减少了体积,减的不多 主要优化了web界面,将我觉得不需要的控件做了隐藏 出图后进行显存回收 固定种子改成了随机种子 原版30步默认,改成了10步 实测感觉影响不大 对电脑硬件有较高要求 内存至少24gb 显存至少20gb 我的4060 16gb出图很卡,前面3张每张100秒左右 1024分辨率的 后面好像更卡了 没有高配硬件,不想优化了 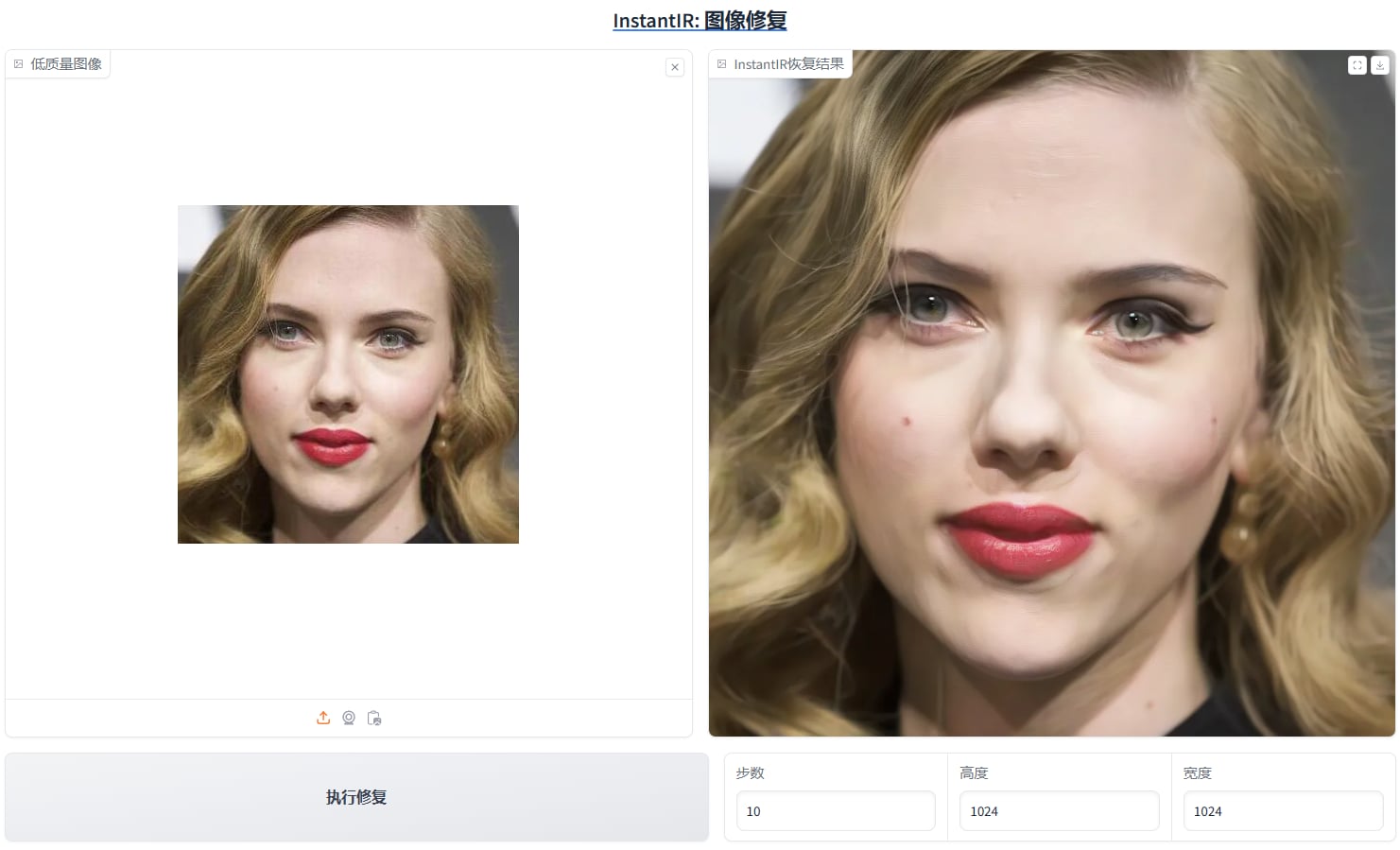 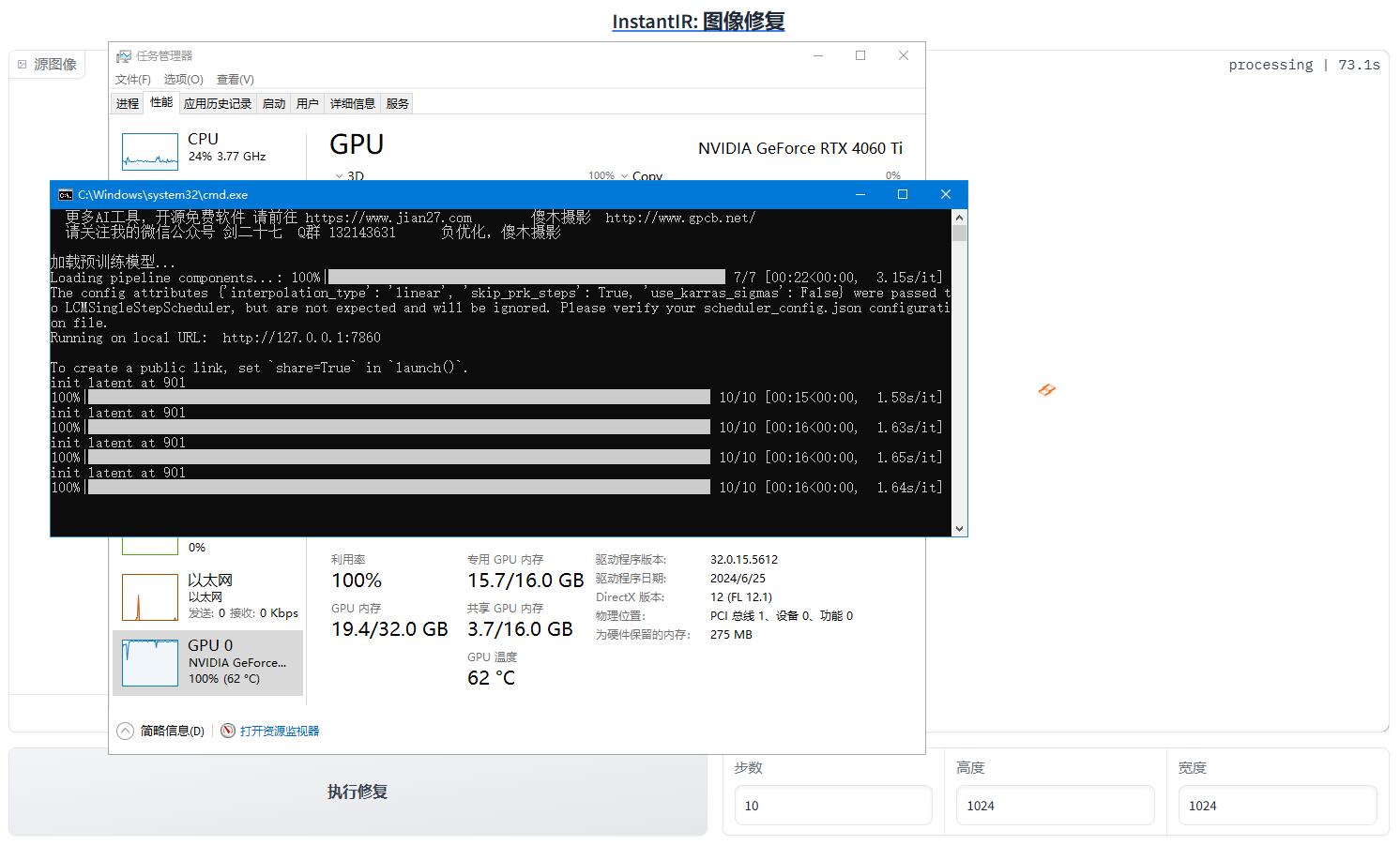 17.35gb 回复可见 隐藏内容,请前往内页查看详情
nstantIR,AI图像修复 nstantIR 是一个在 GitHub 上的开源项目 InstantIR 采用了深度学习技术。通过使用深度神经网络,InstantIR 学习图像的特征,从而更好地理解图像的内容。 用于图像的相似度计算,实现快速准确的还原修复受损的图片。 jian27打包 [https://www.jian27.com/html/2418.html](https://www.jian27.com/html/2418.html) 本站二次负优化 减少了体积,减的不多 主要优化了web界面,将我觉得不需要的控件做了隐藏 出图后进行显存回收 固定种子改成了随机种子 原版30步默认,改成了10步 实测感觉影响不大 对电脑硬件有较高要求 内存至少24gb 显存至少20gb 我的4060 16gb出图很卡,前面3张每张100秒左右 1024分辨率的 后面好像更卡了 没有高配硬件,不想优化了   17.35gb 回复可见 隐藏内容,请前往内页查看详情 -
ComfyUI-精简版,懒人包 ComfyUI-精简版,懒人包 目录结构  运行界面 运行后如果不是下图的工作流,可能需要手工载入工作流 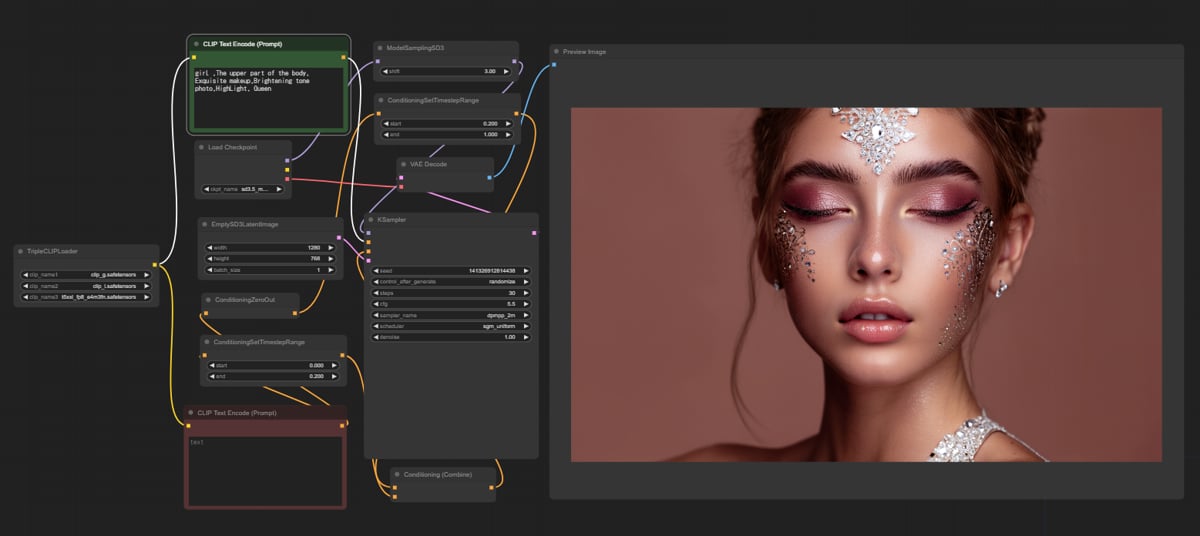 4060 8gb显卡,显存占用6.8,实际占用6gb左右 4060 16gb显卡,显存占用最高达14.7gb 程序会针对实际硬件资源充分利用显存 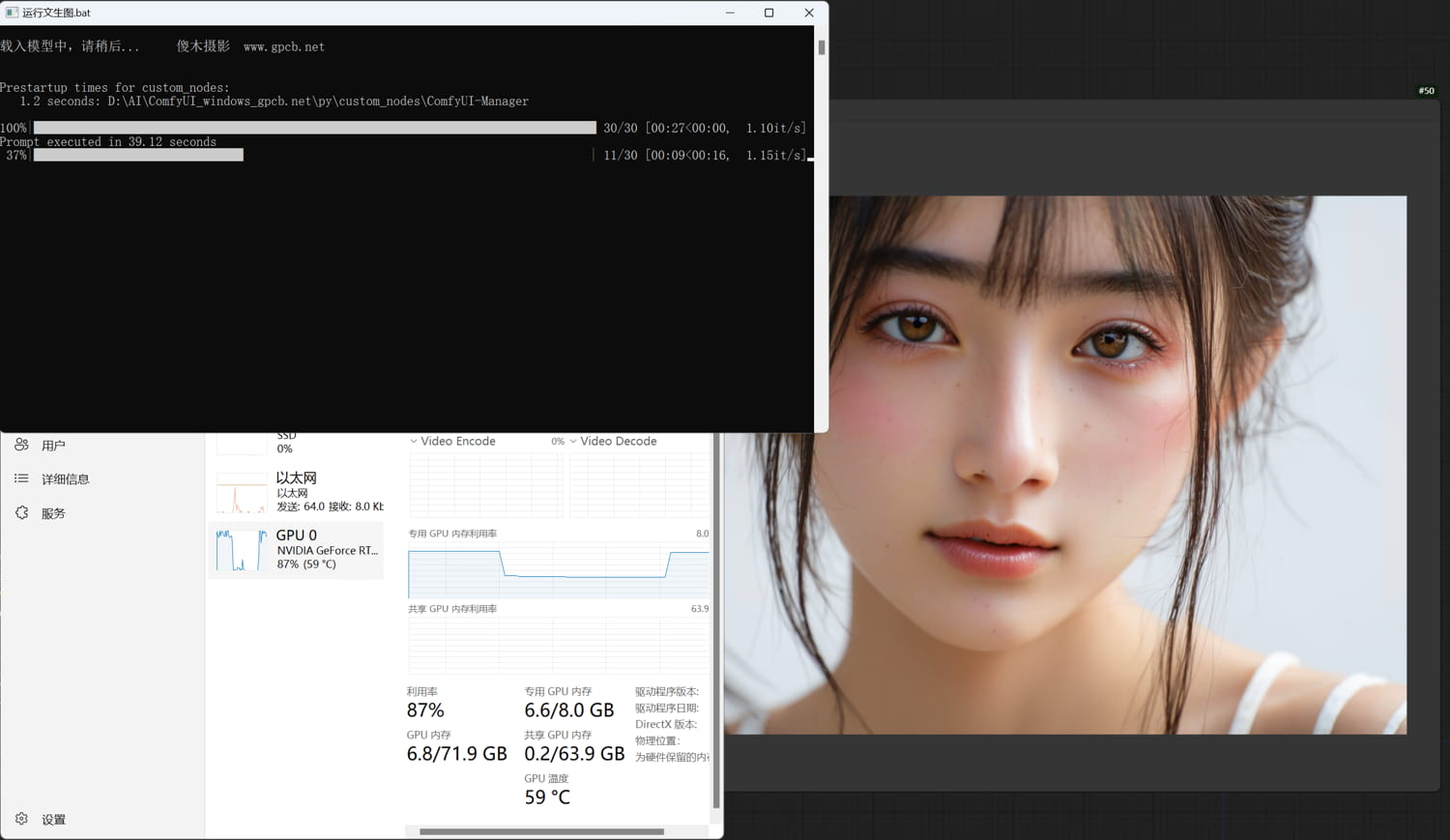 不会用的可以百度,不喂饭 本站负优化版,10.7gb,带模型,解压即用 硬件要求,16gb内存,8gb黄皮显存 回复可见 隐藏内容,请前往内页查看详情
-
F5-TTS-main,根据参考语音生成语音,懒人包 F5-TTS-main,根据参考语音生成语音 整合包制作:数字生命卡兹克 我不认识他,整合包来自群友分享,在此基础做了界面负优化,把我不想看到的都删除了 用法,上传一段示例语音,例如猪八戒的 打上一段文字,例如唐僧念的那段经文 生成的结果就是,猪八戒的音色念唐僧的经文 可以理解为语音克隆 参考语音只需要15秒的范本即可 已精简界面,已删除不需要的模型 原版功能挺多的,还有什么多人对话那种,例如悟空和八戒对话 这些都删除了 为什么删除? 就连简单的文本生成语音都是玩具级别 还谈什么多人对话? 经测试,有吞字想象,有不连贯想象,有标点符号停顿过短想象(抢读) 等等等等一系列问题,如果想拿去商用,还是算了 只是玩具级别,发出来只是让大伙看看,目前AI到了什么境界 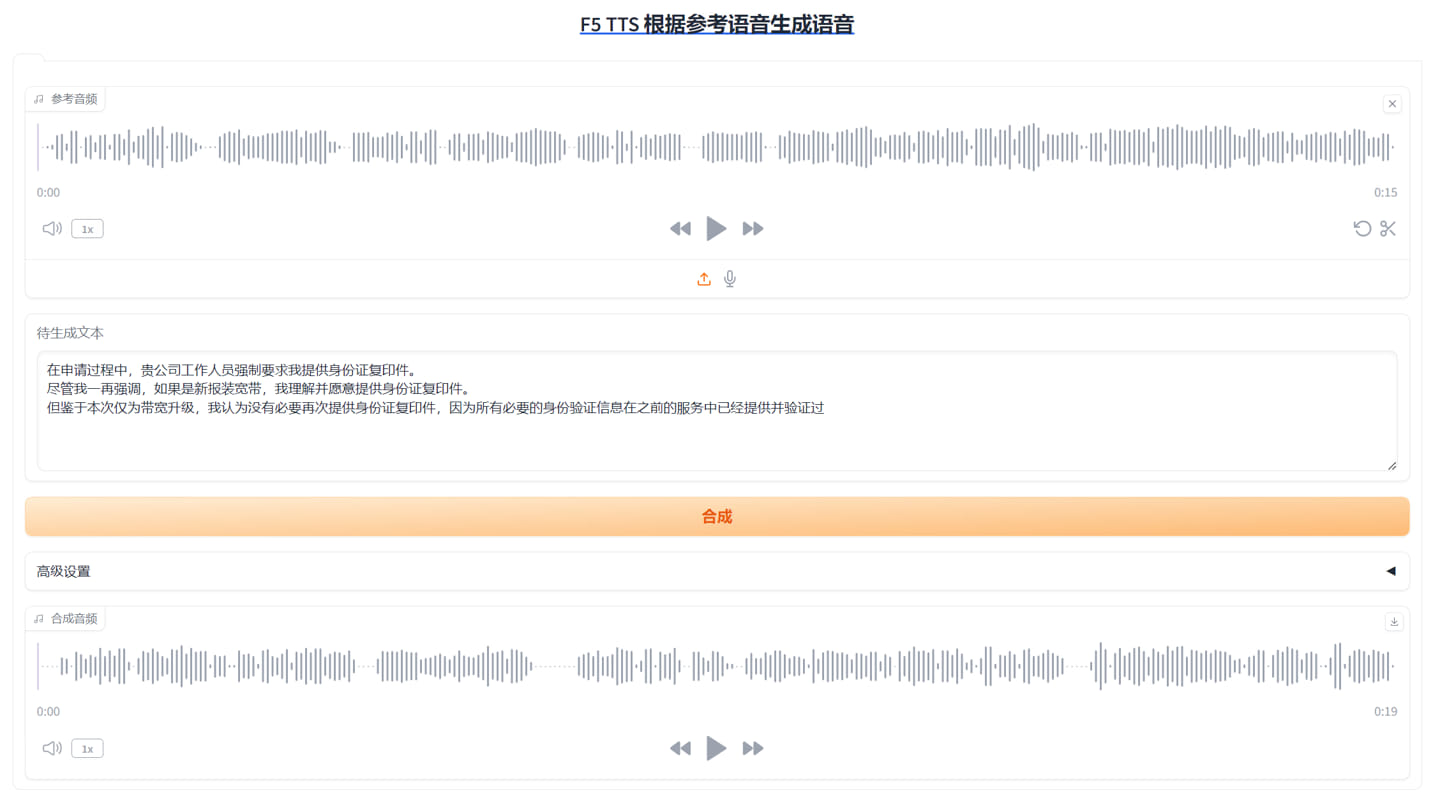 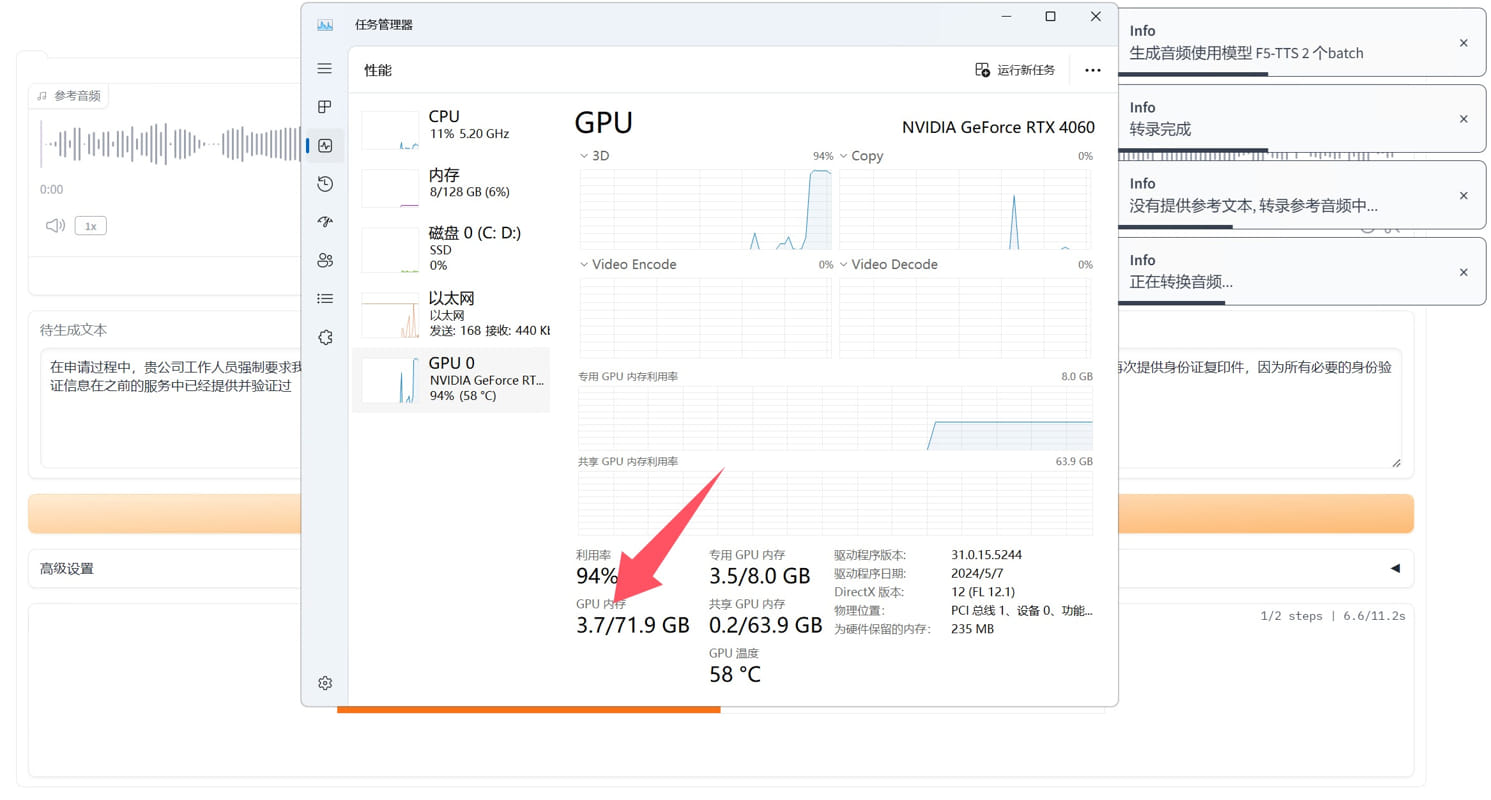 精简后的压缩包4.3gb,原版大小11gb 下载链接 [https://pan.baidu.com/s/11HKrYtgsrArF8kbTP1Vh1g?pwd=gpcb](https://pan.baidu.com/s/11HKrYtgsrArF8kbTP1Vh1g?pwd=gpcb)
-
AI离线大模型加载工具,LM Studio AI离线大模型加载工具,LM Studio 官网连接 [https://lmstudio.ai/](https://lmstudio.ai/) 这个工具其实用了很长时间了 之所以现在才推荐 主要原因是从上一版已支持简体中文语言 谁说并不全面 总好过没有 今天已更新到0.3.5版了 具体更新了啥我也没看懂 反正他升级,我就跟着升级 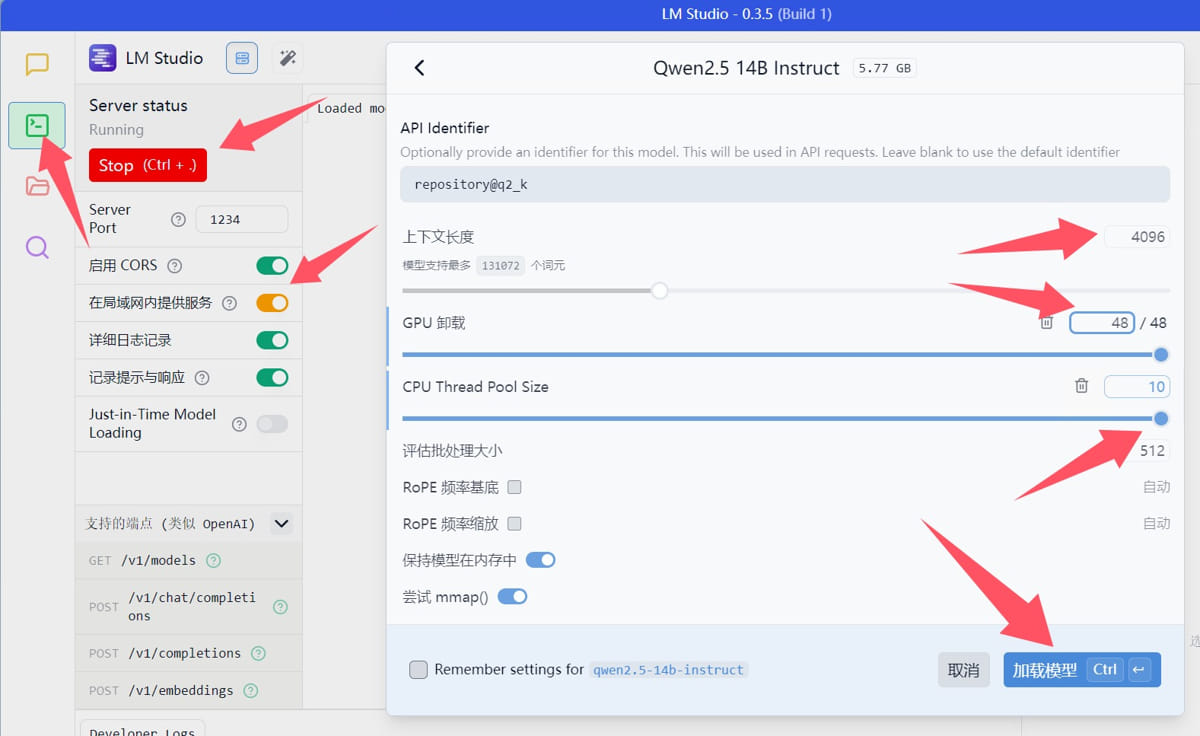 软件免费的 至于模型,那简直太多了 去抱抱脸下载任意gguf格式的模型即可 什么千问,llama等等都有官方量化好的 根据显卡显存下载对应模型 如果需要参数大的,例如14B的模型 只有8gb显存的话,可以看看模型的量化后体积 公司电脑4060 8gb显存 我加载了qwen2.5-14b-instruct-q2_k 是的,这个是14B大小,140亿参数 如果fp16的话,大概需要32gb显存 我下载的是q2-k量化版,所以加载完成不到7gb显存占用 可以在自己电脑安装加载模型 还可以以服务端部署在公司内网 其他用户通过api方式访问 这个软件是目前我用过最稳定的 还有三个软件都支持加载gguf模型 但是都不太稳定,就不推荐了
-
UltraPixel高分辨率文生图 UltraPixel高分辨率文生图 UltraPixel是一种由华为诺亚方舟实验室联合香港科技大学共同开发的超高清图像合成架构,旨在生成具有丰富细节的高质量图像,其分辨率可以从1K一直延伸至6K。 无需进一步微调,直接支持的最高分辨率为4K,例如,3840 * 2160,2048 * 2048等 简单来说,不用超分,直接出大图 硬件要求 黄皮显卡必备 勾选低显存模式也需要占用12.4gb显存 至少12gb显存,8gb非常耗时 建议16gb显卡起步 16gb 4060 38秒一张,分辨率1536X1536 8GB显卡启用低显存模式,点击生图按钮后,会假死几分钟!!!不要关闭,等等就好 8gb显卡不开低显存模式,5分半钟一张,1024*1024 勾选低显存模式3分45秒 本站负优化内容: 已改成GUI窗口模式,去掉原先浏览器界面了 页面汉化 显存回收 部分逻辑修正 原版没有随机种子,已改成随机种子 出图自动保存到OUT文件夹 点击GUI界面的图片以系统默认看图软件打开 仅保留必要控件,例如图高图宽以及是否低显存模式 增加配置文件保存信息 下次运行时调取上次你设置的宽高等配置信息 jian27打包 [https://www.jian27.com/html/379.html](https://www.jian27.com/html/379.html) 开源项目页面 [https://github.com/catcathh/UltraPixel](https://github.com/catcathh/UltraPixel) 以下是官方建议的关键词填写范式(PS:项目支持简单的中文关键词,例如直接填写:“一个女孩” 也是可以出图的) Tips: To generate aesthetic images, use detailed prompts with specific descriptions. It's recommended to include elements such as the subject, background, colors, lighting, and mood, and enhance your prompts with high-quality modifiers like "high quality", "rich detail", "8k", "photo-realistic", "cinematic", and "perfection". For example, use "A breathtaking sunset over a serene mountain range, with vibrant orange and purple hues in the sky, high quality, rich detail, 8k, photo-realistic, cinematic lighting, perfection". Be concise but detailed, specific and clear, and experiment with different word combinations for the best results. 提示:要生成美观的图像,请使用带有特定描述的详细提示。建议包括主题,背景,颜色,灯光和情绪等元素,并使用高质量的修饰符增强提示,如“高质量”,“丰富的细节”,“8k”,“照片级逼真”,“电影”和“完美”。例如,使用“在宁静的山脉上令人惊叹的日落,天空中充满活力的橙子和紫色色调,高质量,丰富的细节,8k,照片般逼真,电影般的照明,完美”。简洁但详细,具体而清晰,并尝试不同的单词组合以获得最佳效果。 这是生成的图片,有压缩  加载模型需要大约5秒钟  12gb显卡可以勾选低显存模式 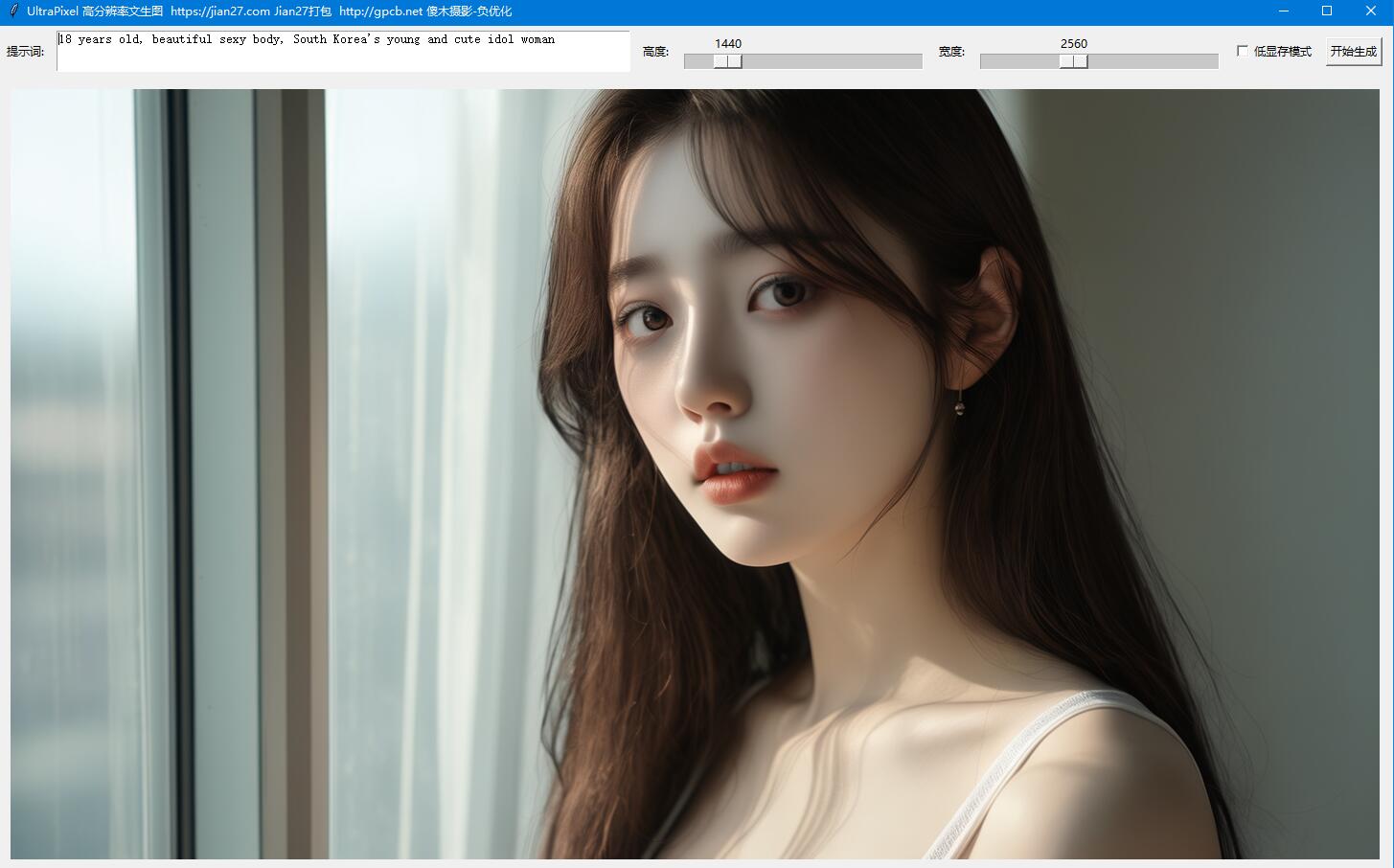 2024-10-16 更新,改成gui窗口,保存配置文件 百度云盘连接,17.5gb,回复可见 隐藏内容,请前往内页查看详情
-
diffusers-image-outpaint,智能扩图工具,懒人包,有更新 diffusers-image-outpaint,智能扩图工具,懒人包 ps原版有扩图的,但是老美不给用 Diffusers Image Outpaint 是一个在 Hugging Face 上的开源项目, 它为图像外绘(image outpainting)提供了强大的工具和解决方案。 本站独有负优化 增加了常见图片比例 图片完成输出后,自动保存到out目录 可以将扩展后的图片当做原图,继续扩展,无极限 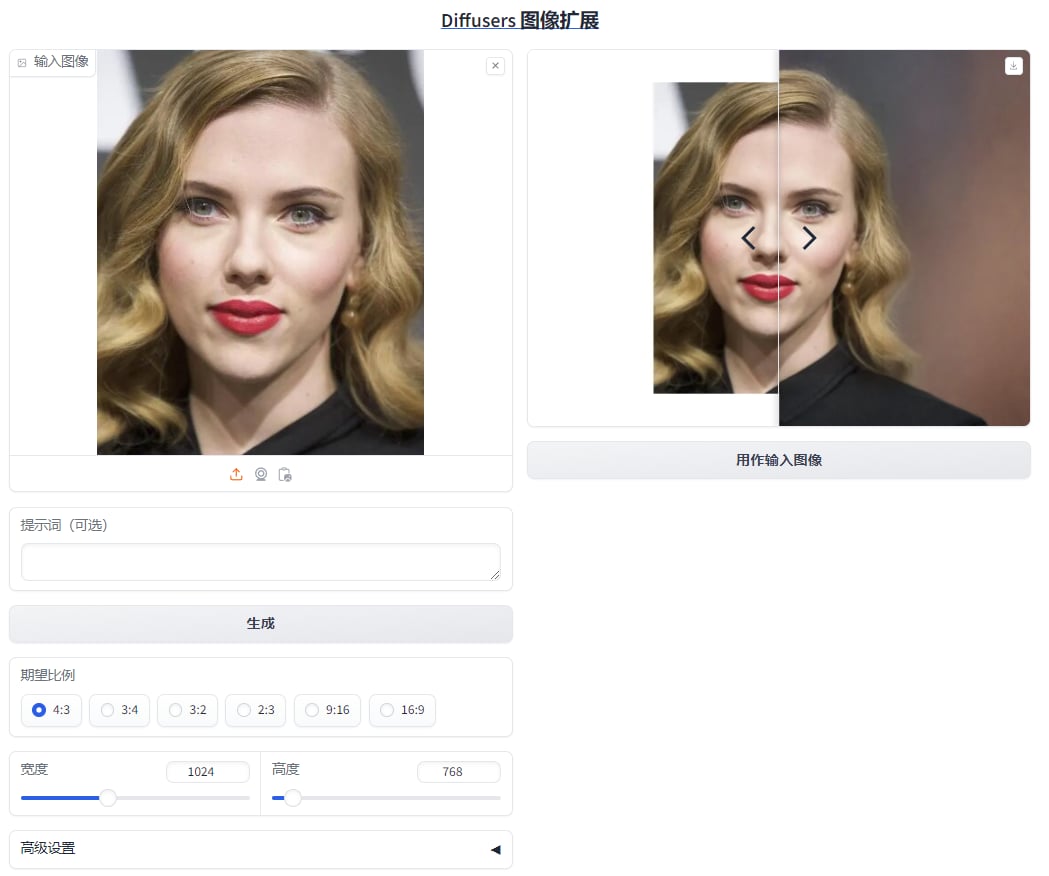 [Jian27 打包](https://www.jian27.com/html/1069.html) 该项目不建议8gb显卡用户使用 最低消耗14gb显存 推荐16gb显卡使用,4060 TIS 16gb显卡,7秒一张 2024-09-30更新: 压缩包15gb,下载地址回复可见,百度网盘 上个版本的bug已更改好了 增加了自定义比例尺寸 固定比例也支持更改尺寸 例如,选择4:3 此时想更改长宽尺寸,直接拖动长边,改到你需要的尺寸 图高会自动等比更改 优化了显存回收机制 最大边长改大到2048 最大边长会导致显存暴涨 另外,遇到不扩图,直接给图片加边框的情况,请缩小点分辨率或者加大点分辨率 可能是模型卡脖子了,不是软件bug  2024-10-14,更新,旧版初始化运行时可能会重新下载模型 此版在两台机测试ok,没有更多电脑做测试了 隐藏内容,请前往内页查看详情
-
腾讯开源GFPGAN图片无损放大,一键懒人包 腾讯开源GFPGAN,一键懒人包 集显不用下载了 A卡也不用下载了 依赖CUDA生态 3年前的老项目了 网上应该是有其他人做的懒人包的 我懒得找 看见模型更新到1.4了 重新打包了下 老样子,删除了一切不我想看见的 尽可能精简体积且不影响输出效果 这个项目对显卡要求较低,大概4gb黄皮显卡都可以流畅运行 1080像素放大4倍,不过消耗约2gb显存 我有尝试将4000万像素放大2倍,显存消耗11.2gb,最终显示内存不足而失败 又选择了4500x3000分辨率图片放大2倍,显存占用4.2gb 选择了6600*4400像素的照片,约2500万像素的,消耗显存9gb,内存约18gb,需要分解204块 这已超出软件使用范畴 软件是用来你修复老旧照片的,意味着低分辨率低像素效果才明显 总体来说,十分优秀    inp 将待放大图片放在这个文件夹 out 是完成放大图片输出文件夹,放大完成后会自动打开 gfpgan 是程序文件夹,不用管 将图片放在inp文件夹,即可批量处理 图片名不能有中文空格等 解压后,双击 无损放大.bat 按键盘上的2或者4,然后按回车 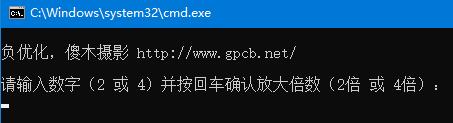 超分放大不挑图片类型,风景人文都可以 极端情况是没什么用的 例如,你拿育儿园大合影来超分,那不现实 模型里面数据大多是老外,绿豆大小的人头超分后大多变成老外了 如果有识别到人脸,则会生成对比图,如果没识别出来,则不会有 如果拿大合影来超分,最后一步会对人脸进行切片对比,这一步会消耗较多时间 注意事项,此项目是以人脸优先的,意思是,一张图片,优先识别人脸,背景什么的,大概率不会动,或者是效果不怎么好 如果修复没有人脸信息的风景照,可能没什么效果 负优化,傻木摄影 http://www.gpcb.net/ 项目地址 [https://github.com/TencentARC/GFPGAN](https://github.com/TencentARC/GFPGAN) 更新,显著减小了体积 链接: [https://pan.baidu.com/s/1cTLyNDBIL55SFIkYOLwytQ?pwd=gpcb](https://pan.baidu.com/s/1cTLyNDBIL55SFIkYOLwytQ?pwd=gpcb) [https://www.123pan.com/s/fp3Njv-zcwld.html](https://www.123pan.com/s/fp3Njv-zcwld.html) 提取码:gpcb






