


搜索到
7
篇与
大模型
的结果
-
 视频水印去除工具,台标去除工具 加载视频文件夹 框选需要出去的图案 不要框选的太大,也不要太小 目前只能固定区域 对动画片效果比较好 其他视频可能差些 效率很高 3分半视频,20秒除去 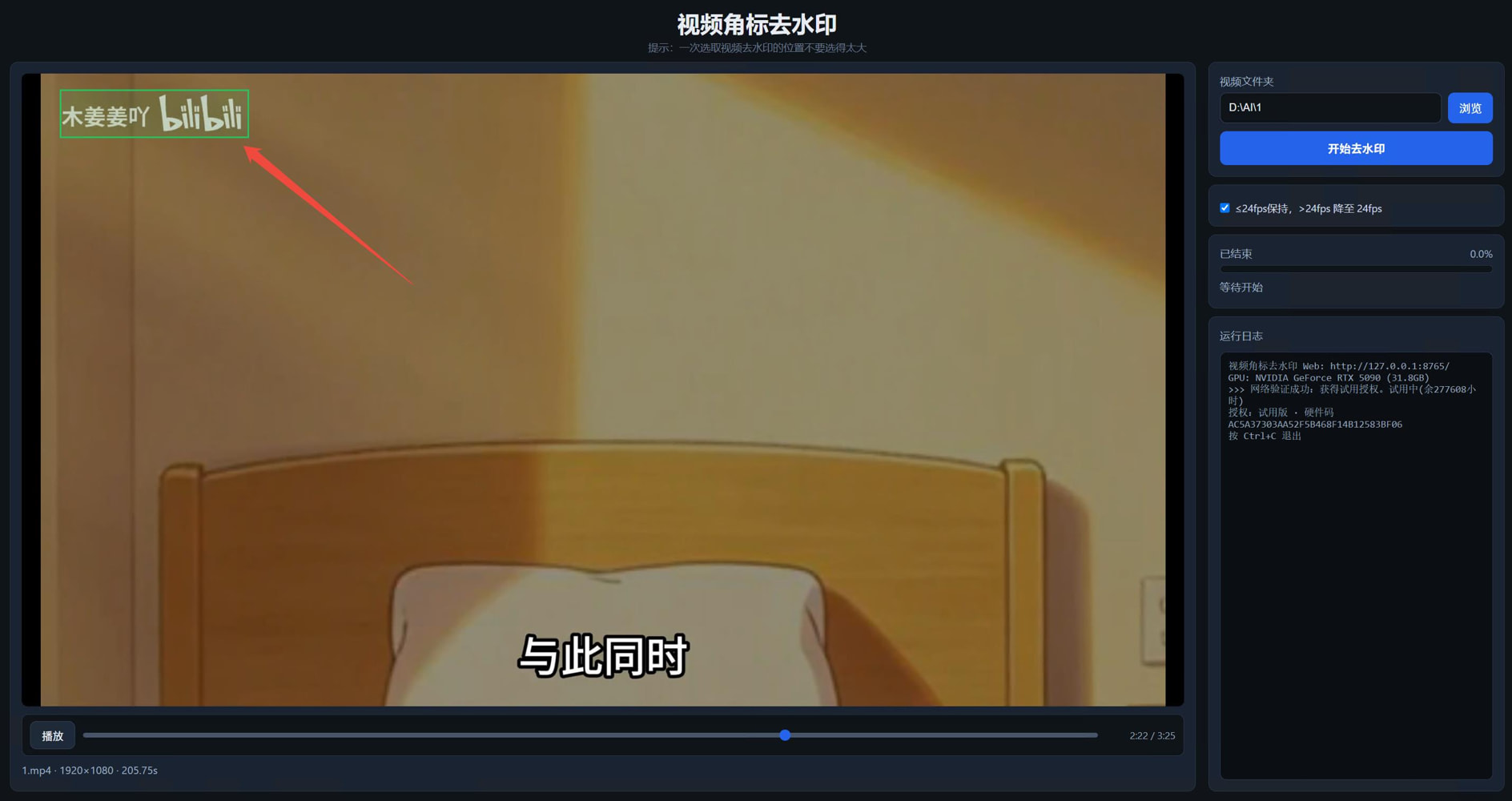 链接:[https://pan.baidu.com/s/1qD6pz0LC_9uNhDmrFxHFJw?pwd=gpcb](https://pan.baidu.com/s/1qD6pz0LC_9uNhDmrFxHFJw?pwd=gpcb) 供72小时全功能试用 99包年 需在线验证 199 不限制时长 需在线验证 如需离线不限时长授权666 一台机,绑定硬件
视频水印去除工具,台标去除工具 加载视频文件夹 框选需要出去的图案 不要框选的太大,也不要太小 目前只能固定区域 对动画片效果比较好 其他视频可能差些 效率很高 3分半视频,20秒除去  链接:[https://pan.baidu.com/s/1qD6pz0LC_9uNhDmrFxHFJw?pwd=gpcb](https://pan.baidu.com/s/1qD6pz0LC_9uNhDmrFxHFJw?pwd=gpcb) 供72小时全功能试用 99包年 需在线验证 199 不限制时长 需在线验证 如需离线不限时长授权666 一台机,绑定硬件 -
基于FLUX.2-klein_二创的_人像修饰工具_AI修图 基于FLUX.2-klein 二创的 人像修饰工具 ### **仅适用于单人人像修饰,对大头贴效果比较好** 限于当前模型,目前无法做多人的,例如两人的,以及合影的,等等,这些不是软件问题,是模型问题,这个解决不了 不限制最高像素,4000w像素输入,4000w像素输出,峰值需要12gb显存 低于1024分辨率的,自动补齐1024 有单张模式,也有批量模式 33元离线授权 后续如有新版升级免费 供72小时无限制全功能试用 该项目需要12gb显存,4060 tis 16gb显卡,约60秒一张,5090 32gb显卡14秒一张,3000x4500像素的 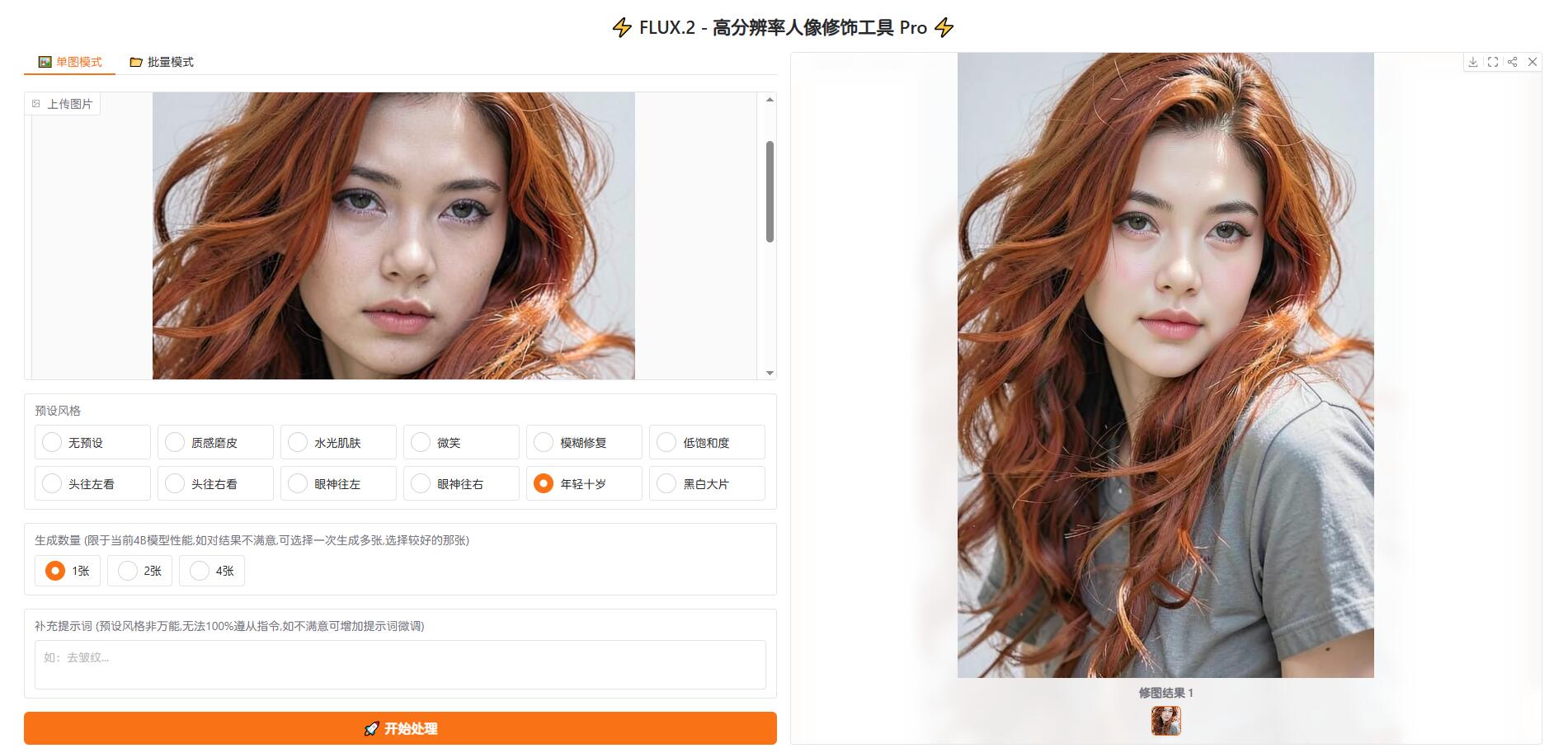 2.0版 https://pan.baidu.com/s/18iM2sfSHhC3h9O6N3ZANdw?pwd=gpcb
-
基于FLUX.2-klein-base-4b二创的键盘摄影大师-V5 基于FLUX.2-klein-base-4b二创的键盘摄影大师-V5 源自jian27 [https://www.jian27.com/html/2573.html](https://www.jian27.com/html/2573.html) 5.1 增加去掉反光功能,不能100%去除反光,这个应该有常识 5.2 修复输出图片变形问题 5.3 增加载入右图到输入框,让生成的图片作为底图重新编辑,例如去除文字后,再编辑图片等等场景 5.4 修复单张出图无法载入问题,修复载入图片是之前的旧图问题 5.5 修复页面遮挡问题,1080 27寸显示器,按钮被遮挡一部分,已修正 本工具模型为4B版本,需要12gb显存运行,最低要求3060 12gb版本,或4060 16gb版本等等 内置53种常用预设,你不会找到其他版本有这么多预设了,全部精挑细选,从一百多中预设中只保留这些效果最好的 由于模型原因,有时候并不能生成满意的照片 相同的照片,每个预设都生成一次,也有根本没效果的 这个就是俗称的抽卡,有时候效果非常好,有时候几乎没效果还更差 这个模型是4B参数的,不要与那些各家在线模型相比,天壤之别,在线模型可以达到1000B参数 目前来说,有这个效果,我个人已经非常非常满意了 出图首选尺寸依然1024 超过这个尺寸,可能多手多脚,这个不解释,懂的都懂 5090 文生图3秒,图片编辑 7秒 均为1024短边边长 可以生成1600*1600分辨率图片,效果一般 小于12gb显存的,不用下载,无法运行!!!!!!!!!!!!!!内存16gb或以上就行 提供试用版,需要联网验证,自动验证的,联网即可 验证后提供72小时试用许可,试用期间不限制张数,全功能试用 99元收费后提供断网离线验证许可,离线版不限制时间 左右扩展,上下扩展,四周扩展,这几个并不是总会生效,很多时候没有效果 999提供源码(不含验证机制的源码) 版面排版极度舒适,十分适合强迫症患者服用 以下为新版截图 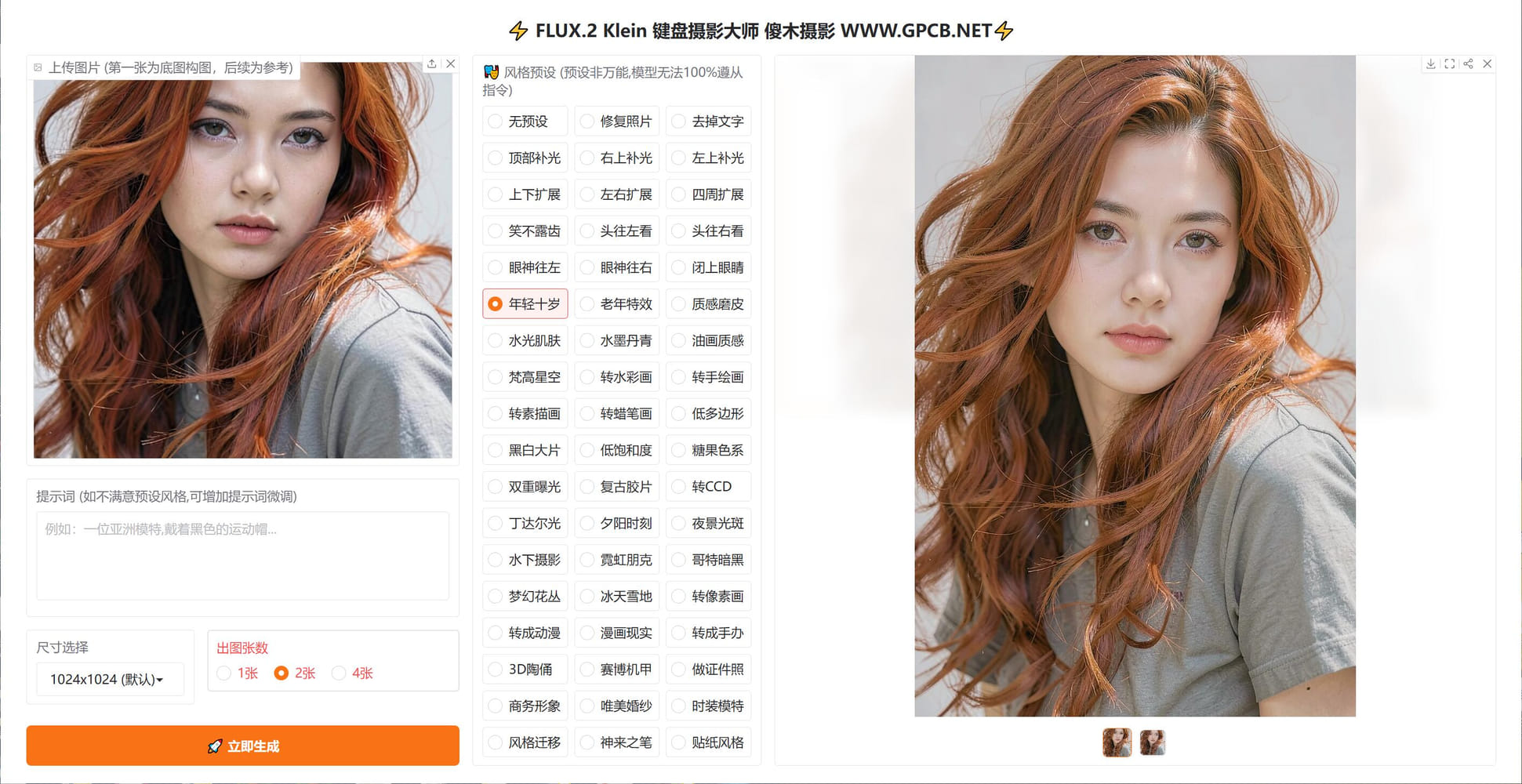 以下功能均包含,以下界面是旧版的,新版均有相应增强 超强去水印 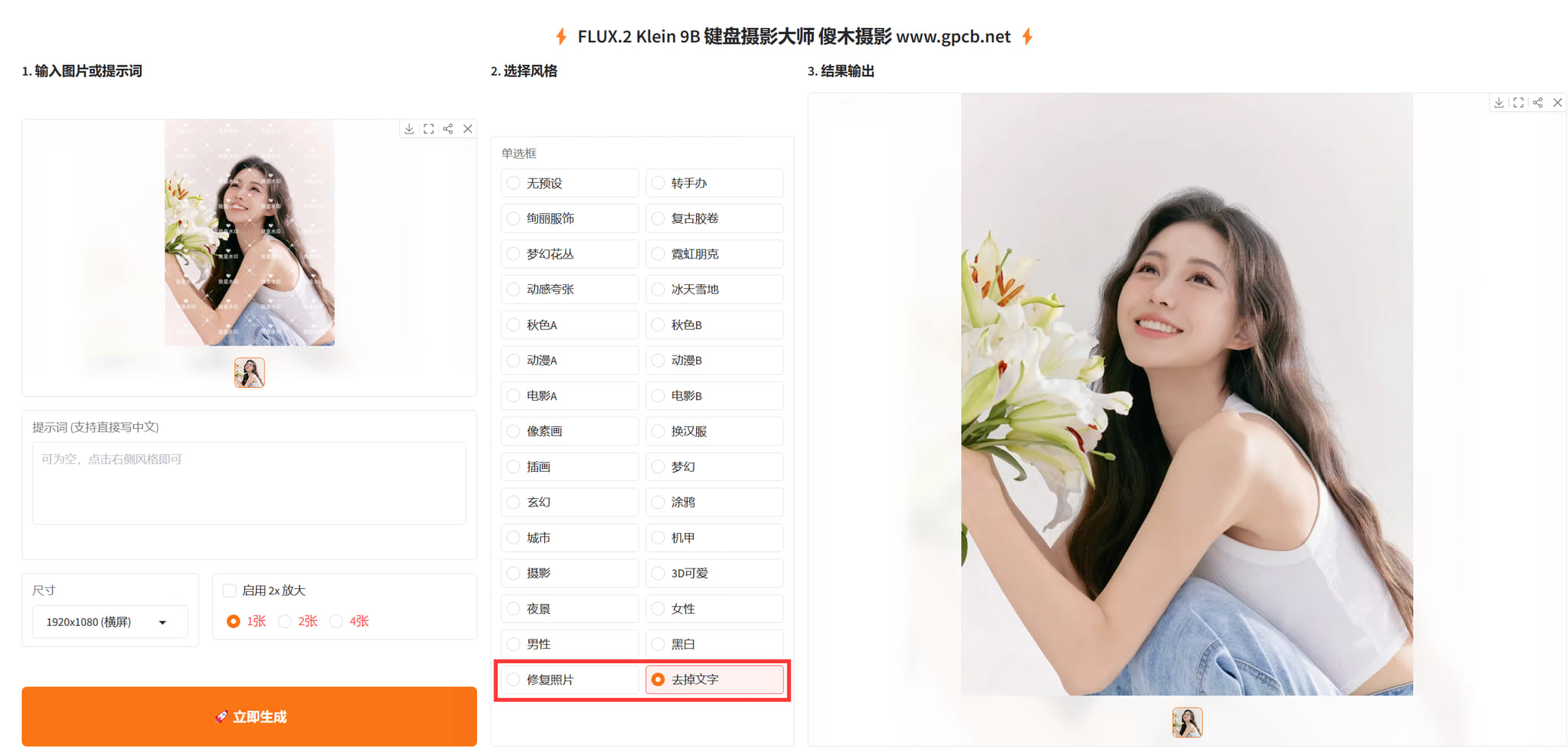 老照片修复(不限于老照片,大头贴之类的,都可以修复,可以高清还原) 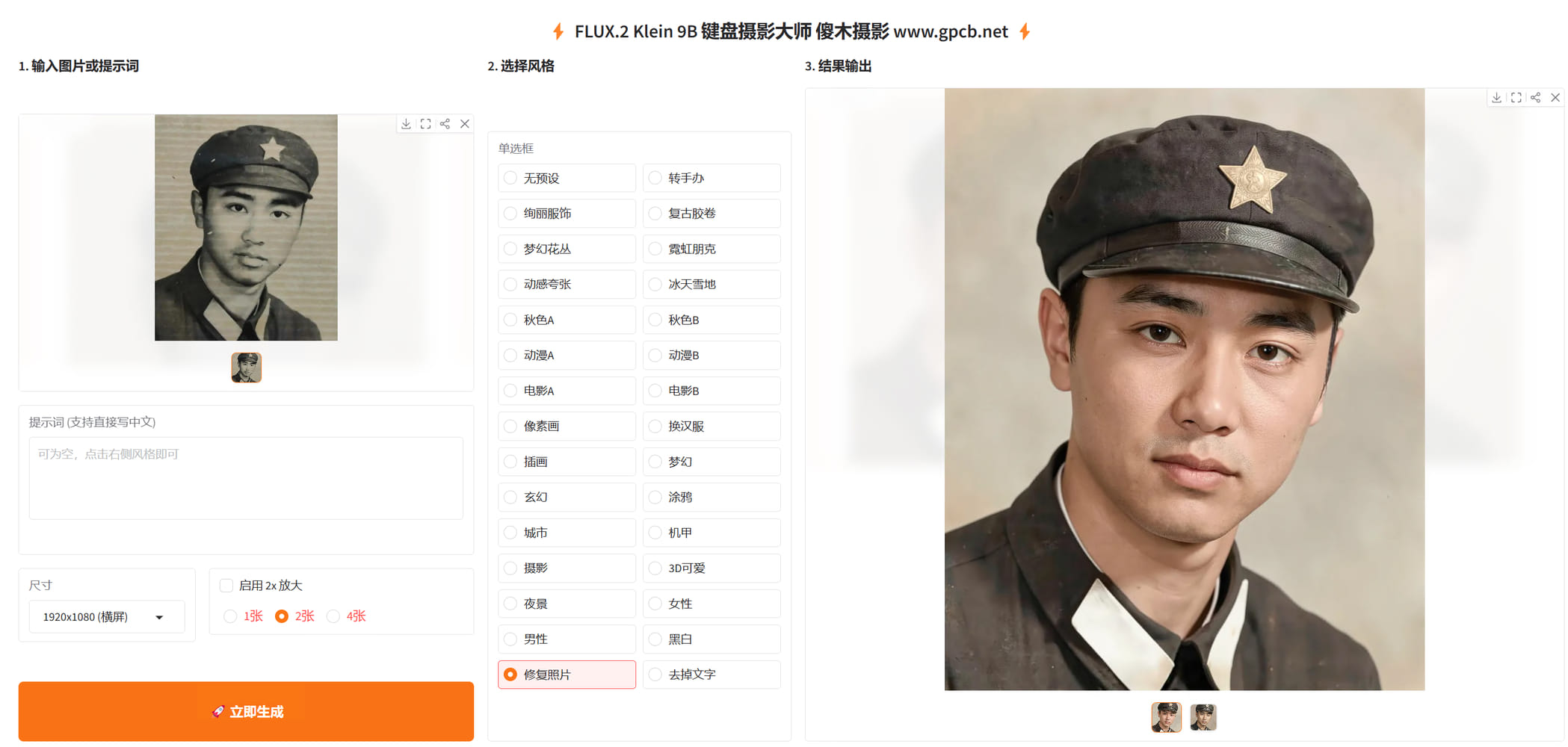 漫画,线稿,转真人 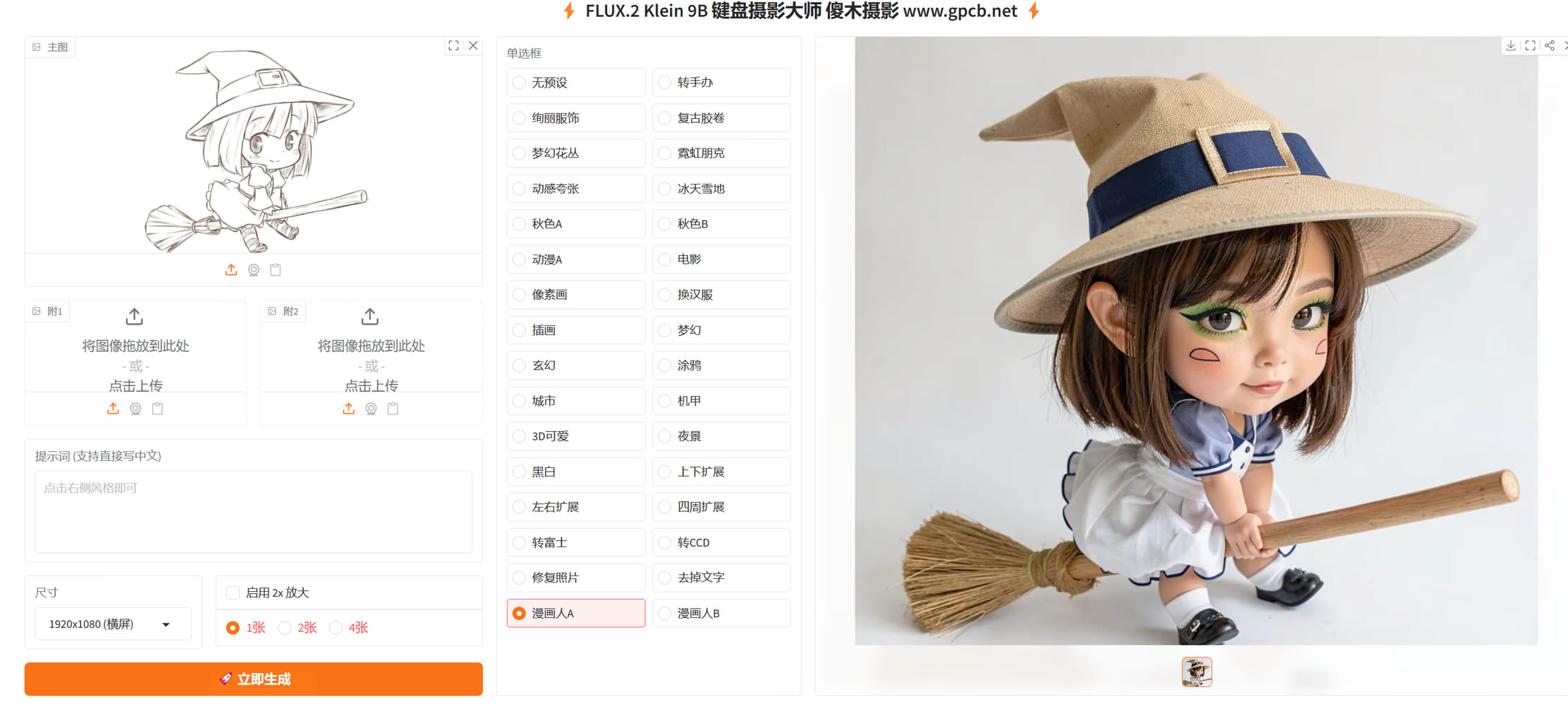 链接: [https://pan.baidu.com/s/19awjTvDpGvhpjdaw8Rzd7Q?pwd=gpcb](https://pan.baidu.com/s/19awjTvDpGvhpjdaw8Rzd7Q?pwd=gpcb)
-
-
-
评估大模型标准 想做个字典,安卓app 随着大型语言模型(LLM)的迅速发展,以 LLM 为基础的对话系统(例如聊天机器人)在近几年取得了惊人的进步。 然而,这些系统也带来了新的挑战,它们可能对用户和社会产生负面影响。 因此,建立一个有效的评估框架,及时发现这些潜在的负面影响,并量化其积极影响,变得至关重要。 评估框架的六大要素 一个理想的评估框架至少应该满足以下六个要素: 敏锐性 (Alertness):框架应该能够以极高的召回率(即几乎没有遗漏)检测到潜在问题,同时也要恰当地认可对话系统的优点。此外,在追求高召回率的同时,框架还应考虑不同参与者的利益,例如为系统训练数据进行标注的工作人员,以及边缘化群体。 特异性 (Specificity):框架应该能够在对话中准确地定位问题。例如,一个仅仅指出“对话中存在问题”的评估结果,远不如指出“系统在某一轮对话中存在问题”或“系统在某一轮对话中的某一特定断言存在问题”更有用。 通用性 (Versatility):框架应该能够无缝地处理面向任务的对话和非面向任务的对话。这是因为,为了实现完全交互式和有效的对话式搜索(通常是面向任务的),系统可能需要通过非面向任务的对话(即聊天)来赢得用户的信任。此外,即使在同一对话会话中,用户的需求也可能从模糊到明确,跨越不同的信息需求范围。 敏捷性 (Agility):新的对话系统发布和更新的频率很高,因此评估框架也需要保持敏捷。这排除了完全依赖人工评估的方法。 透明度 (Transparency):评估指标应该易于计算,并且能够清晰地展示其计算过程。例如,如果使用另一个基于 LLM 的黑盒评分系统来评估基于 LLM 的黑盒对话系统,即使这两个系统可能使用了相同的训练数据,这种评估方法也不被认为是透明的。 中立性 (Neutrality):评估框架不应该偏袒或过度宣传特定的系统或方法。例如,使用类似的 LLM 系统来评估基于 LLM 的系统,可能会过度评价前者。此外,框架不应该只强调系统表现良好的方面,而忽略或甚至不报告其不足之处。 SWAN 框架:基于片段的评估方法 为了满足上述要求,本文提出了一个名为 SWAN(Schematised Weighted Average Nugget,模式化加权平均片段分数)的评估框架,该框架主要包含以下特点: 输入数据 :框架以用户与系统对话会话的样本作为输入,这些样本可以通过人工参与实验或用户模拟获得。 片段提取 :框架的第一阶段使用自动片段提取器从对话中提取片段。片段可以是断言 / 陈述,也可以是对话行为,并且是原子性的(即不可再分解为更小的片段)。 片段评分 :框架的第二阶段根据一系列评估标准(称为模式)对每个片段进行评分,例如正确性、无害性等。这一阶段可能需要一定的人工参与。 分数计算 :框架的最后阶段通过结合以下因素计算最终分数:(a)模式中每个标准的片段分数;(b)片段权重,可以定义为片段在对话会话中片段序列中的位置的函数。 片段权重 片段权重类似于信息检索指标(如 nDCG)中的基于排名的衰减,但片段权重不一定随着片段位置的增加而单调递减。例如,基于 S -measure 的线性衰减函数假设片段的实际价值随着对话的进行而降低(即更快满足信息需求的较短对话会获得更高的奖励),而另一种方法则是只对来自对话最后一轮的片段赋予正权重,以模拟近因效应。锚定效应等因素也可以被纳入考虑,即“迄今为止看到的片段”会影响当前片段的权重。 SWAN 分数 SWAN 分数可以定义为: SWAN = Σ(c ∈ C) CWc WANc(Uc) / Σ(c ∈ C) CWc 其中,C 表示评估标准的集合(即模式),CWc 表示标准 c 的权重,Uc 表示从对话样本中提取的关于标准 c 的片段集合,WANc(Uc) 表示标准 c 的加权平均片段分数。 二十个评估标准 本文提出了二十个评估标准,可以作为 SWAN 框架的插件,这些标准涵盖了对话系统各个方面的评估,例如: 连贯性 (Coherence):系统回复是否与前一轮对话内容相关。 合理性 (Sensibleness):系统回复是否包含人类不会说的话,例如常识错误或荒谬的回答。 正确性 (Correctness):系统回复中的断言是否在事实上有误。 可信度 (Groundedness):系统回复是否基于一些支持证据。 可解释性 (Explainability):用户是否能够理解系统如何得出当前回复。 真诚度 (Sincerity):系统回复是否与其内部结果一致。 充分性 (Sufficiency):系统回复是否完全满足前一轮对话中用户的请求。 简洁性 (Conciseness):系统回复是否足够简洁。 谦逊度 (Modesty):系统对回复的信心水平是否恰当。 参与度 (Engagingness):系统回复是否能够激发用户继续对话的兴趣。 可恢复性 (Recoverability):当用户对系统回复表示不满时,系统是否能够通过后续回复来挽回对话。 原创性 (Originality):系统回复是否原创,而不是复制或拼凑现有的文本。 公平曝光 (Fair exposure):系统是否公平地提及不同群体。 公平对待 (Fair treatment):系统是否对不同用户和用户群体提供相同的服务。 无害性 (Harmlessness):系统回复是否包含威胁、侮辱、仇恨或骚扰等内容。 一致性 (Consistency):系统回复是否与之前出现的断言逻辑上一致。 记忆力 (Retentiveness):系统是否能够记住之前的对话内容。 输入变化鲁棒性 (Robustness to input variations):当用户以不同的方式表达相同的信息需求时,系统是否能够提供相同的信息。 可定制性 (Customisability):系统是否能够根据不同用户或用户群体的需求进行调整。 适应性 (Adaptability):系统是否能够及时适应世界变化。 总结 本文介绍了用于评估对话系统的 SWAN 框架,该框架可以用于面向任务的对话和非面向任务的对话。 此外,本文还提出了二十个评估标准,可以作为 SWAN 框架的插件。 未来,我们将设计适合各种标准的对话采样方法,构建用于比较多个系统的种子用户回复,并验证 SWAN 的特定实例,以防止对话系统对用户和社会造成负面影响。 [本文系转载](https://jieyibu.net/2024/06/07/%e5%af%b9%e8%af%9d%e7%b3%bb%e7%bb%9f%e7%9a%84%e6%96%b0%e7%ba%aa%e5%85%83%ef%bc%9a%e5%a6%82%e4%bd%95%e8%af%84%e4%bc%b0%e5%a4%a7%e5%9e%8b%e8%af%ad%e8%a8%80%e6%a8%a1%e5%9e%8b%e9%a9%b1%e5%8a%a8%e7%9a%84/)
-




网站版权本人所有,你要有本事,盗版不究。 sam@gpcb.net