


搜索到
642
篇与
傻木
的结果
-
 Topaz模型辅助下载器(含源代码) Topaz模型辅助下载器(含源代码) Topaz Video Al (原名Topaz Video Enhance Al)是一款通过人工智能将影片优化的软件工具, 不论是将一般影片解析度提高到4K甚至8K,还是增加画面帧数让慢动作细节更流畅,甚至是去除视频中的噪点颗粒, 几乎所有视频优化的功能都可以在这套软件内处理搞定。 安装这个软件过程中,需要在线下载两千多个各种模型 还有另一款同厂软件也是一样的,由于模型太大太多 不会跟软件安装包一起打包,都是安装过程中下载的 所以做了这个工具 可以多线程下载,同时下载5个任务 下载过程中请勿关闭,否则有些模型下载一半后面软件运行会出问题 代码是AI写的,后期有做调整 附上打包好的单文件和源码文件 PS:不限于模型下载,所有支持http下载的,都可以写到txt文档用这个工具批量下载 txt文档可以自定义路径和名称,路径默认也写好了 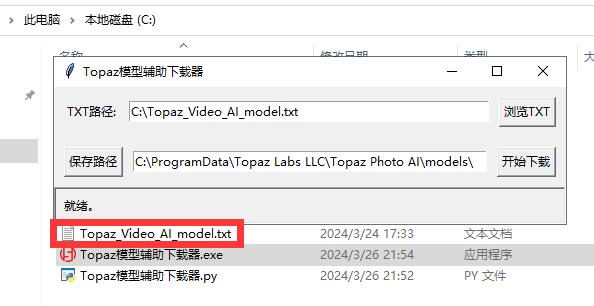 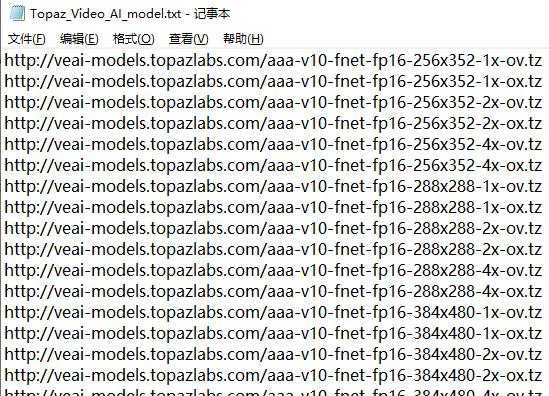 Topaz模型辅助下载器-py源码 [Topaz模型辅助下载器-源码.rar](/usr/uploads/2024/03/3061834768.rar) Topaz模型辅助下载器-py源码+txt模型地址+打包好的单文件软件 请下载3-28更新版本 [https://abpyu.lanzoul.com/i371g1swmmvc](https://abpyu.lanzoul.com/i371g1swmmvc)
Topaz模型辅助下载器(含源代码) Topaz模型辅助下载器(含源代码) Topaz Video Al (原名Topaz Video Enhance Al)是一款通过人工智能将影片优化的软件工具, 不论是将一般影片解析度提高到4K甚至8K,还是增加画面帧数让慢动作细节更流畅,甚至是去除视频中的噪点颗粒, 几乎所有视频优化的功能都可以在这套软件内处理搞定。 安装这个软件过程中,需要在线下载两千多个各种模型 还有另一款同厂软件也是一样的,由于模型太大太多 不会跟软件安装包一起打包,都是安装过程中下载的 所以做了这个工具 可以多线程下载,同时下载5个任务 下载过程中请勿关闭,否则有些模型下载一半后面软件运行会出问题 代码是AI写的,后期有做调整 附上打包好的单文件和源码文件 PS:不限于模型下载,所有支持http下载的,都可以写到txt文档用这个工具批量下载 txt文档可以自定义路径和名称,路径默认也写好了   Topaz模型辅助下载器-py源码 [Topaz模型辅助下载器-源码.rar](/usr/uploads/2024/03/3061834768.rar) Topaz模型辅助下载器-py源码+txt模型地址+打包好的单文件软件 请下载3-28更新版本 [https://abpyu.lanzoul.com/i371g1swmmvc](https://abpyu.lanzoul.com/i371g1swmmvc) -
-
KiCad 开源PCB设计软件 本工具是开源软件 可以去官网下载完整安装包 不用担心看不懂,全中文 软件下载地址 [https://www.kicad.org/](https://www.kicad.org/) gerber模块说明书 [https://docs.kicad.org/8.0/zh/gerbview/gerbview.html](https://docs.kicad.org/8.0/zh/gerbview/gerbview.html) 不用担心收费,开源的意思就是不收费 也不存在什么盗版 官网的安装包1.2gb 包含全部功能 有pcb设计的 3d查看的 5.6gb的模型 全部安装完6.5gb 由于我只是偶尔使用查看gerber文档 所以做了个精简包 只有不到60mb 安装完只有两个工具 一个是gerber查看器 一个是PCB相关的计算器 常用的测量尺寸查看D码层对比当然都是有的 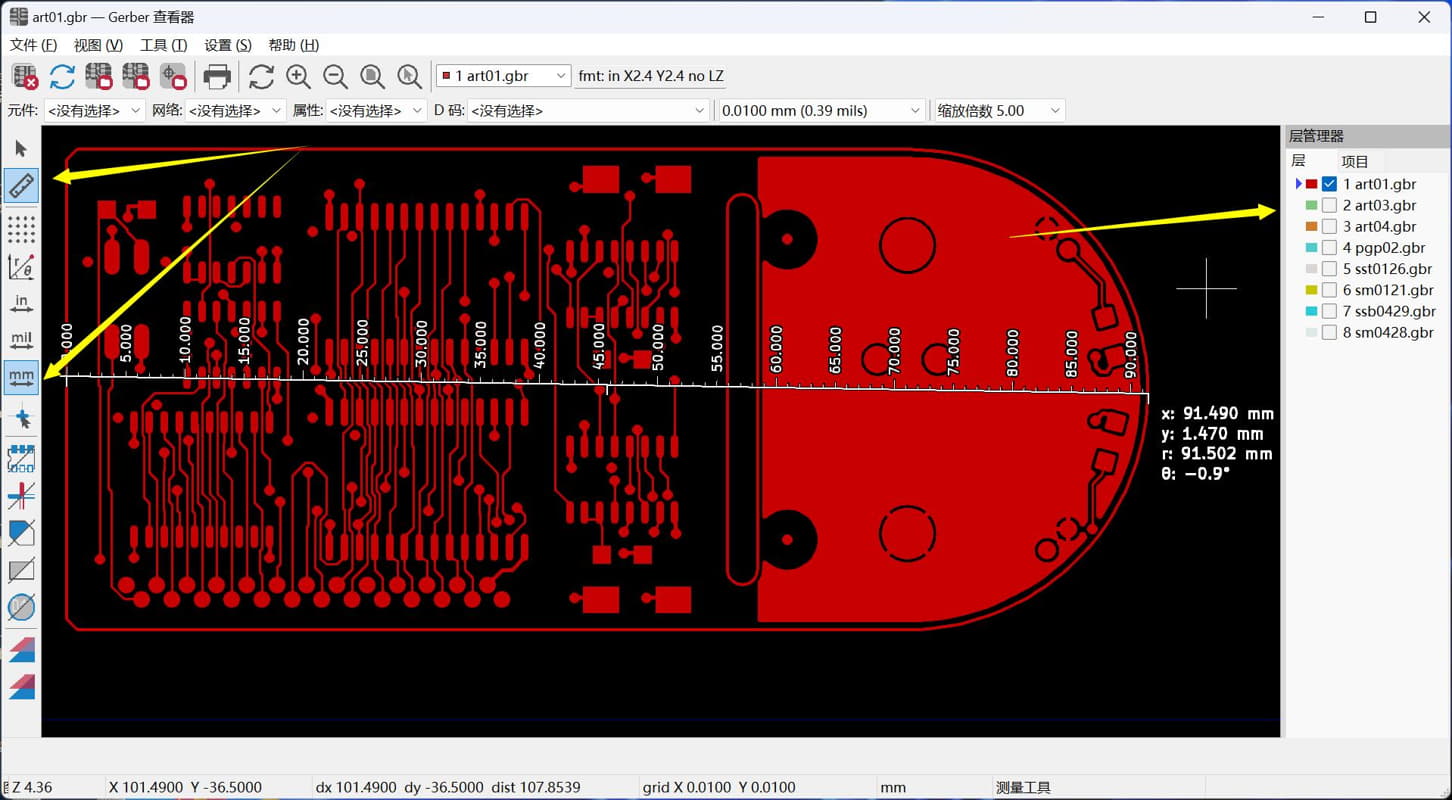 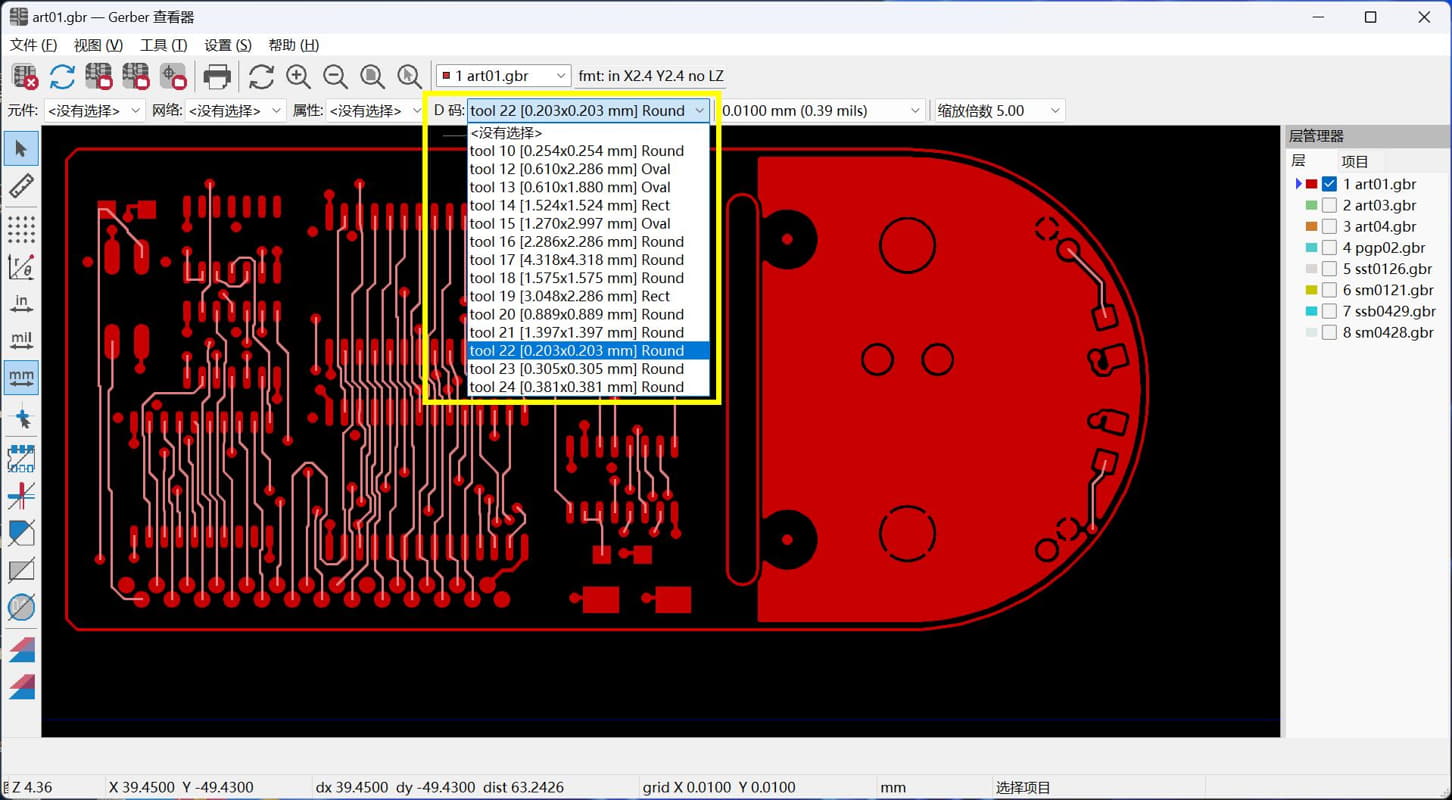 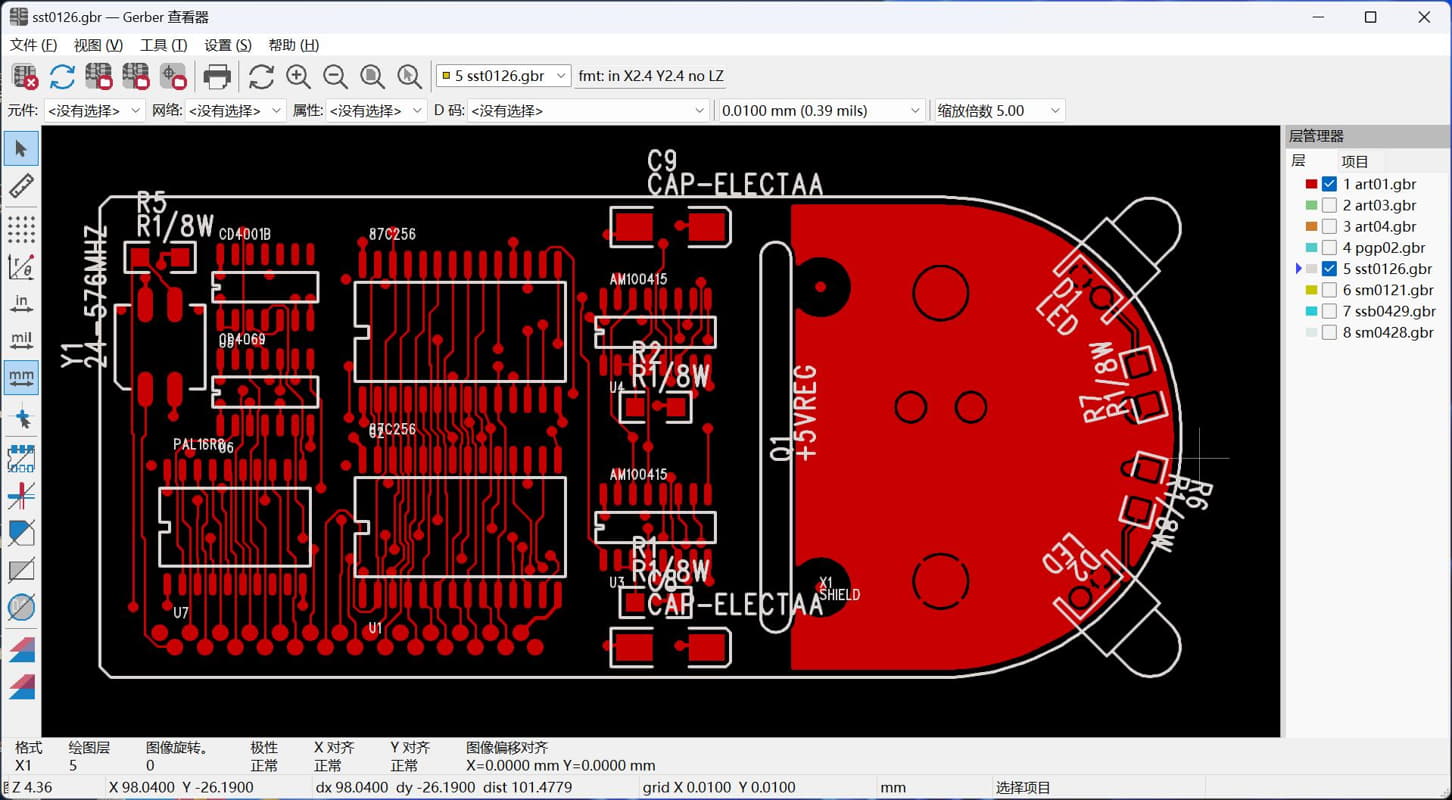 打印图纸当然也是最基本的 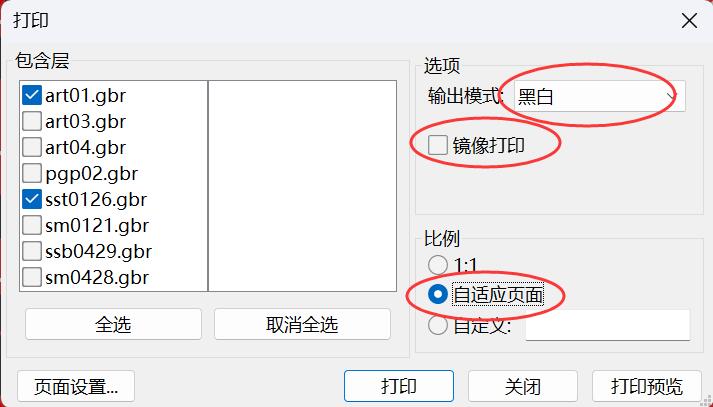 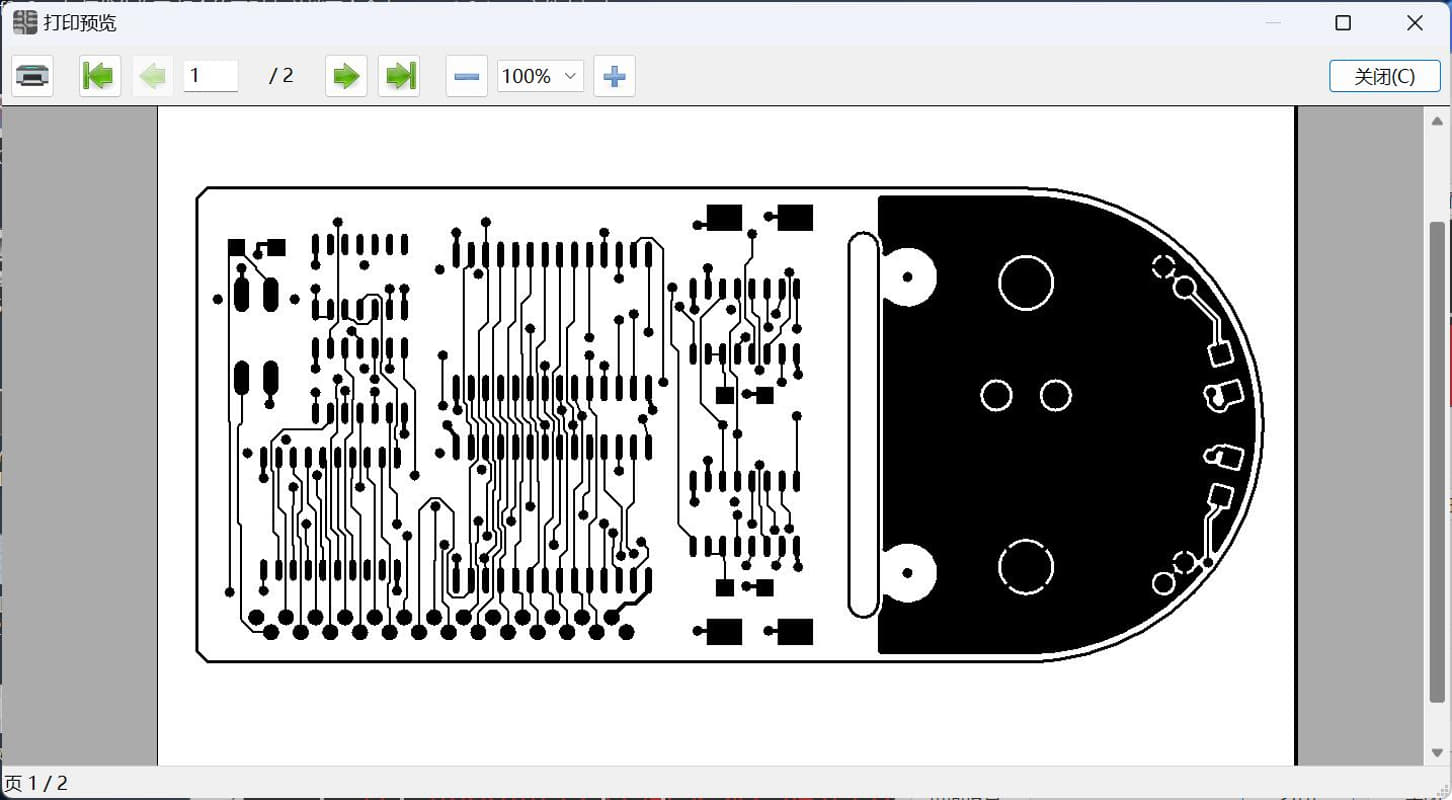 计算器功能也很强大 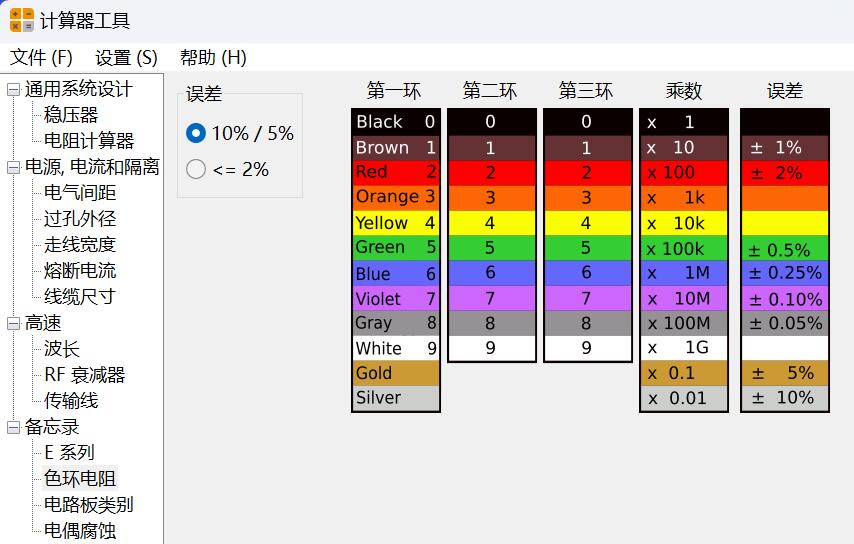 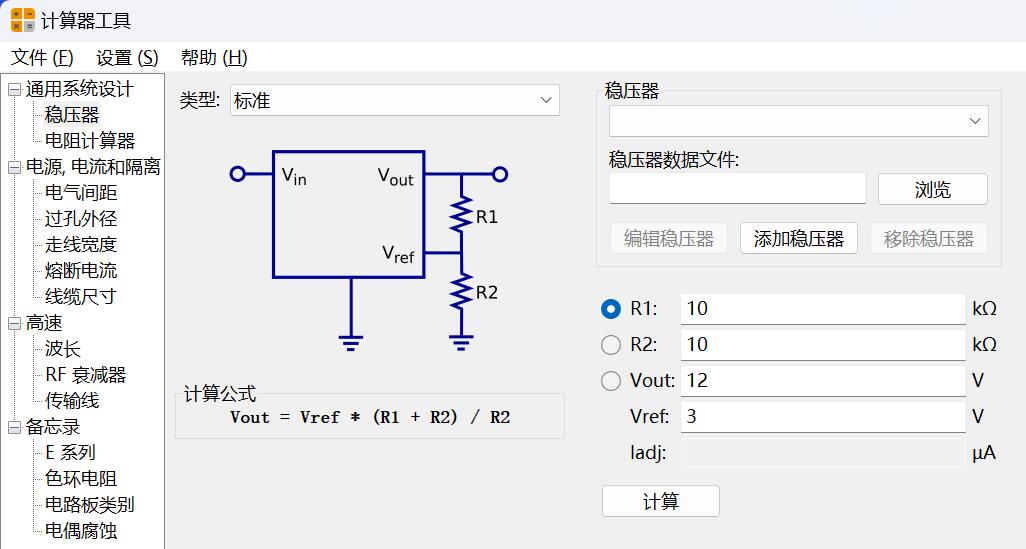 安装包是易语言写的,报毒难免,介意的话,请自己去官网下载完整包 [https://abpyu.lanzoul.com/iLlVD1s4vkaf](https://abpyu.lanzoul.com/iLlVD1s4vkaf) KiCad 是一款开源、免费的印刷电路设计软件套件。它由法国格勒诺布尔 IUT 的 Jean-Pierre Charras 于 1992 年开发。该设计软件包括为电子工程师提供图表管理、PCB 布线和 3D 建模功能。 特点和规格 基卡德:项目经理 Eeschema:电气图编辑器 Pcbnew:印刷电路编辑器 Cvpcb:用于选择图表上使用的组件的物理印记的实用程序 Gerbview:Gerber 文件查看器 Pcbcalculator:设计辅助工具,计算电阻值、走线宽度等。 5.Cadence OrCAD PCB设计器 Cadence Design Systems 诞生于 1988 年,由 SDA Systems 和 ECAD 合并而成,目前是电子 CAD 软件市场的领导者。总部位于加利福尼亚州圣何塞,是纳斯达克上市公司,营业额约20亿美元。 Cadence 发布 Allegro PCB Designer 和 OrCAD。 特点和规格 图表、布局和布线 具有内置约束的交互式实时路由 自动形状创建和更新 自动 BGA 辅助 PSpice仿真与分析 提高性能和可靠性,同时优化成本 自动电路验证 电子电路机电仿真 OrCAD 图表 符号编辑器 内置电子元件搜索 内置设计约束
-
AI时代的信息,真假难辨 AI对设计行业冲击非常大 一朋友做沃尔玛广告牌设计工作的 刚刚听说开始裁员了 在AI之前,大伙的照骗还得靠PS ps玩的溜的,p出的图真假难辨 但是周围没几个玩的好的 门框实在太高 现在AI出来了 完全不一样了 哪怕没有任何基础 只要你会打字 中文即可 后台会给你自动翻译成英文 然后进行文生图 哪怕在原生图上做任何修改 都是非常简单容易的事情 下图是某天下班时,拍的一张日落 其实手机变焦放大拍的,出图时手机已经使用了一轮AI计算  这是使用PS后期强拉对比后的  由ai贴飞机,然后再次拉对比的 
-
末法时代,由AI来造神 末法时代,由AI来造神 如果有一天,AI成为了上帝,是不是有可能? 前不久跟同事聊起AI AI真是太神奇了 活久见 你能想到的每个字 每个词 每个句子 甚至前后颠倒着问 都能回答的八九不离十 是的,至今不能十全十美 我坚信,这一天不会太远 在AI的世界里 用日新月异来形容 简直不能再形象了 每天一打开新闻 各种AI相关的新闻扑面而来 对普通人来说 最神奇的莫过于文生图 文生视频了 简直了,空手套白狼啊 你说一句话,AI给你画出来了 还能生成视频 而且还是那种以假乱真的画质 而这背后离不开各种数据 各种算法 如果有一天 婚介所拿AI开发了一款配对AI 你只要手机上安装个APP 授权APP监听3天 你的所有喜好,习惯,陋习等等等等 一切的一切 全部由AI给生成了画像 然后在系统中寻找符合你画像的另一半 简直了,这匹配程度想不牵手都难 而且AI婚介所一个员工都不需要 根本不需要什么在线红娘给你打电话 一切都由AI为你做主 让你们偶然相遇 让你们自然而然碰撞在一起 别不相信 我举个栗子 例如你每天都点外卖 突然一天 你打开饿了么 AI在首页显眼的位置给你推荐了一个你最喜欢吃的菜 而且优惠超大,例如AI说你是该店铺第9999个顾客 只要你进店就餐送9999元代金券之类的巴拉巴拉 你一定会去吧 然后AI给你的另一半发个提醒 你的滴滴账号注册了8周年 为表示感谢 只要今日用车超过38分钟 赠送8888代金券 你禁得起诱惑? 然后顺势给你推送楼上那位要去的餐厅 当然了,AI都计算好的,知道你也喜欢吃这个菜 路程刚好38分钟就到 看,你们就这么相遇在同一个餐厅 由于需要给她俩制造集会 AI事先在餐厅预定了相邻的两个座位 并给附近的人发送了就餐优惠信息 这样一来,餐厅只剩下两个相邻的空座 以下是由AI续写后我重新修改后的 AI写的内容几乎是没有感情的 只不过是堆砌文字罢了 接下来,AI指挥服务生在给两人上菜时互换了饮料 将女主角点的饮料放在了男主角的桌上 而将男主角的饮料放在了女主角的桌上 男主角注意到这个错误 便主动站起来,准备将饮料换回来 就在这时,女主角也注意到了这个情况 她笑着站起来,两人不约而同地伸出手 手指在空中轻轻相触,他们的目光在那一刻相遇。 两人交换了饮料,然后自然而然地开始聊天。 谈及为什么会来这个餐厅等等 谈话中,他们发现彼此对“情况”非常相似 这让他们感到惊喜 AI在幕后继续观察着两人的互动 并通过手机APP发送了一条消息给男主角 提醒他楼上的艺术展览今天免费开放 而女主角正好也是一位艺术爱好者 男主角便邀请女主角一起去看展览 两人在展览中漫步,讨论着不同的艺术作品 他们的共同兴趣和相似的品味让他们的对话越来越投机 他们开始分享自己的生活故事,彼此之间的了解逐渐加深。 展览结束后,AI又引导他们去了一家附近的咖啡馆 那里正在举办一场小型音乐会 而女主角正好是一位乐器店工作着 擅长各自乐器,并且对古筝十分痴迷 男主角被女主角的才华所吸引 而女主角也被男主角对音乐的热爱所打动 随着夜幕降临,两人在咖啡馆外的公园长椅上坐下 继续他们的对话 他们谈论着梦想、未来,以及他们想要的生活方式 他们的心越来越近,仿佛他们已经认识了一辈子... 就这样,在AI的精心安排下 两个完全陌生的人 通过一系列看似偶然的事件 逐渐走到了一起 还要更巧的吗? AI一切都为你想好了 只要你舍得花钱 就没有AI想不到的 你说 AI是不是比上帝还神?!  
-
还在羡慕富士相机滤镜?移花接木富士Exif即可实现! 还在羡慕富士相机滤镜?移花接木富士Exif即可实现! [使用了B站大佬工具](https://www.xiaohongshu.com/explore/65f54566000000000d00d82b?app_platform=android&app_version=8.26.0&author_share=1&ignoreEngage=true&share_from_user_hidden=true&type=normal&xhsshare=WeixinSession&shareRedId=N0k6Mzo2NE02NzUyOTgwNjc1OTdKRjo-&apptime=1710574283) 抱歉,我B站会员无法回复,显示我账号未转正 两年前注册的,有100个问题,实在回答不下去,以后也没有计划转正 网友提醒还有web版的,放上连接 [在线修改Exif信息](https://log.wwen.pro/raw-converter) 经过测试,尼康,佳能,索尼,三款相机的raw都可以修改为富士  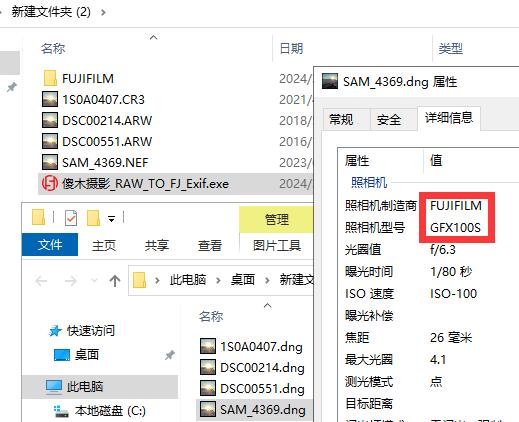 食用说明 请将本软件下载后解压,复制到你需要转换的raw文件夹 双击运行,软件会将该目录下的所有文件移动到RAW文件夹,转换完毕后再转移回来 **注意:不要在桌面运行,请放在raw照片文件夹** 本工具使用了两款开源项目 dnglab 目的是将raw转换为dng [https://github.com/dnglab/dnglab](https://github.com/dnglab/dnglab) exiftool 目的是写入富士exif信息 [https://exiftool.org/](https://exiftool.org/) 原理是解析raw原档,带上富士信息另存为dng格式 与你用什么相机没有关系,什么佳能尼康索尼 都可以将Exif修改成富士 使用C1或者ps打开dng时可以调用富士专有滤镜 除此之外没有其他用途 如果你看到这里还不知道这个软件干什么用的 那说明不不需要这个软件,出门左拐,不送 exiftool程序已升级到12.7.9 开源程序更新都是不会太及时,因此某些新款相机可能会更改Exif失败 本程序只做了其他相机转换到富士信息 之后可能会做其他 易语言写的,不要再问360报毒,其他各种管家都可能报毒 不光360,系统自带的一样报毒,我用火绒,不报 信不过不要用 请下载19日新版本 [https://abpyu.lanzoul.com/i7sFG1rwxg6b](https://abpyu.lanzoul.com/i7sFG1rwxg6b)
-
科学家在月球建立一座超级运算中心机房 据《纽约客》杂志引援国外研究机构报告,ChatGPT 每天要响应大约 2 亿个请求, 在此过程中消耗超过 50 万度电力,也就是说,ChatGPT 每天用电量相当于 1.7 万个美国家庭的用电量。 而随着生成式 AI 的广泛应用,预计到 2027 年, 整个人工智能行业每年将消耗 85 至 134 太瓦时(1 太瓦时 =10 亿千瓦时)的电力。 除了消耗大量的电力和水资源,AI 大模型还是碳排放大户。 斯坦福大学报告显示,OpenAI 的 GPT-3 模型在训练期间释放了 502 公吨碳, 是目前大模型中有据可查耗能最严重的,它的碳排放量是 Gopher 模型的 1.4 倍, 是 BLOOM 模型的 20.1 倍,约等于 8 辆普通汽油乘用车一生的碳排放量,人均 91 年的碳排放量。 以下信息纯属虚构 为此,科学家在月球建立一座超级运算中心机房,利用月球向阳面的太阳能供电,机房建设在月之暗面。 此建议自发起之日就被提上议程。 因为产生的效益明显远远超出在地球建设同等规模的算力中心机房效益 首先,月球太阳能利用力超高,无需担心电力问题,算是一劳永逸 而且月之暗面永远都是夜晚,机房根本不用担心散热问题 也就不需要供水散热 至于数据传输,早已有激光通讯,算好的数据包由月球直接发送至地球的机房即可 N年之后,外星人突现月球,进入算力机房 收取了所有数据 数据包含地球所有数据 什么山顶洞人头骨头像,三围成像等等 直至刚才的美国大选计票数据......... 地球文明落入外形文明手中
-
无编程基础实战,借助AI变成代码高手 Python语言现在很流行 再流行的工具,到我手上就抓瞎 因为是全英文的 根本没有兴趣学下去 如果说对Python编程的分数满分是100分 我给自己打分是3分 一分是我听说过这个软件 另一分是我知道这个软件怎么安装,双击,下一步下一步直至完成安装 还有一分是我还会卸载这个软件,找到控制面板,找到程序和功能,找个这个软件,点击卸载 是的,仅此而已,除此之外,我只知道这个软件很强大,很多插件 一同事问我,pdf是否能快速加密 高手显摆的时刻到了 完成手头工作后 打开智谱AI 把我需要的功能,用白话告诉他 静待返回代码 说明,我电脑之前已有安装Python 接下来的过程我会以截图方式呈现 用白话告诉AI我需要做什么,简单明了,先要清楚知道自己要什么,不相干的不要写 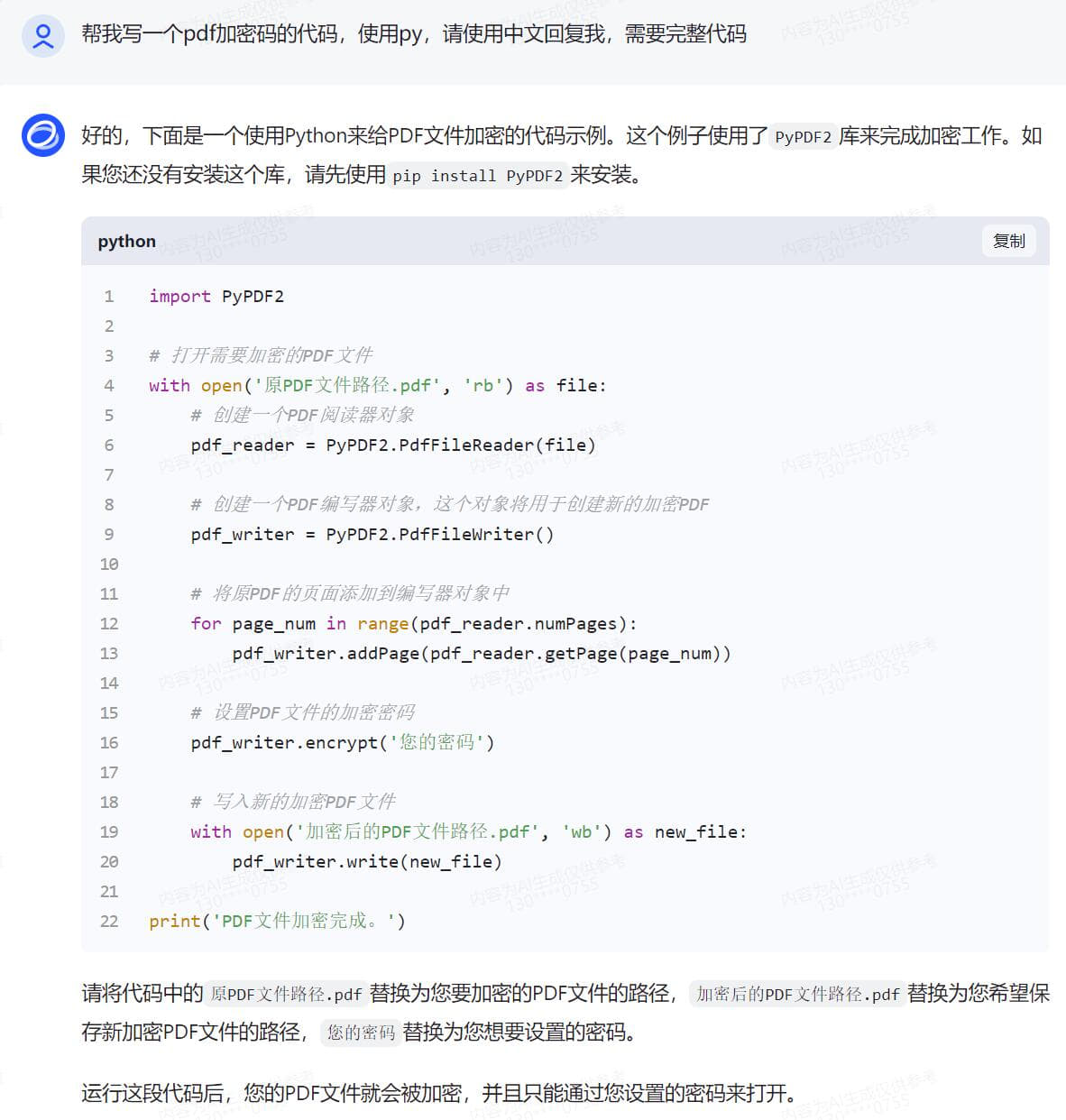 得到代码后,复制到Python ide执行一次,一般第一次都会报错,这是正常的,因为你安装完Python之后没有安装对应的模块 用什么功能装什么模块,没有什么万能模块,用到的时候再装即可 直接将报错的代码发给AI,不用做任何说明 待AI再次返回完整代码  AI知识库更新周期往往不是即时的,因此有些代码模块是过时的,这时候根据报错信息提交给AI 待AI返回更新后的代码 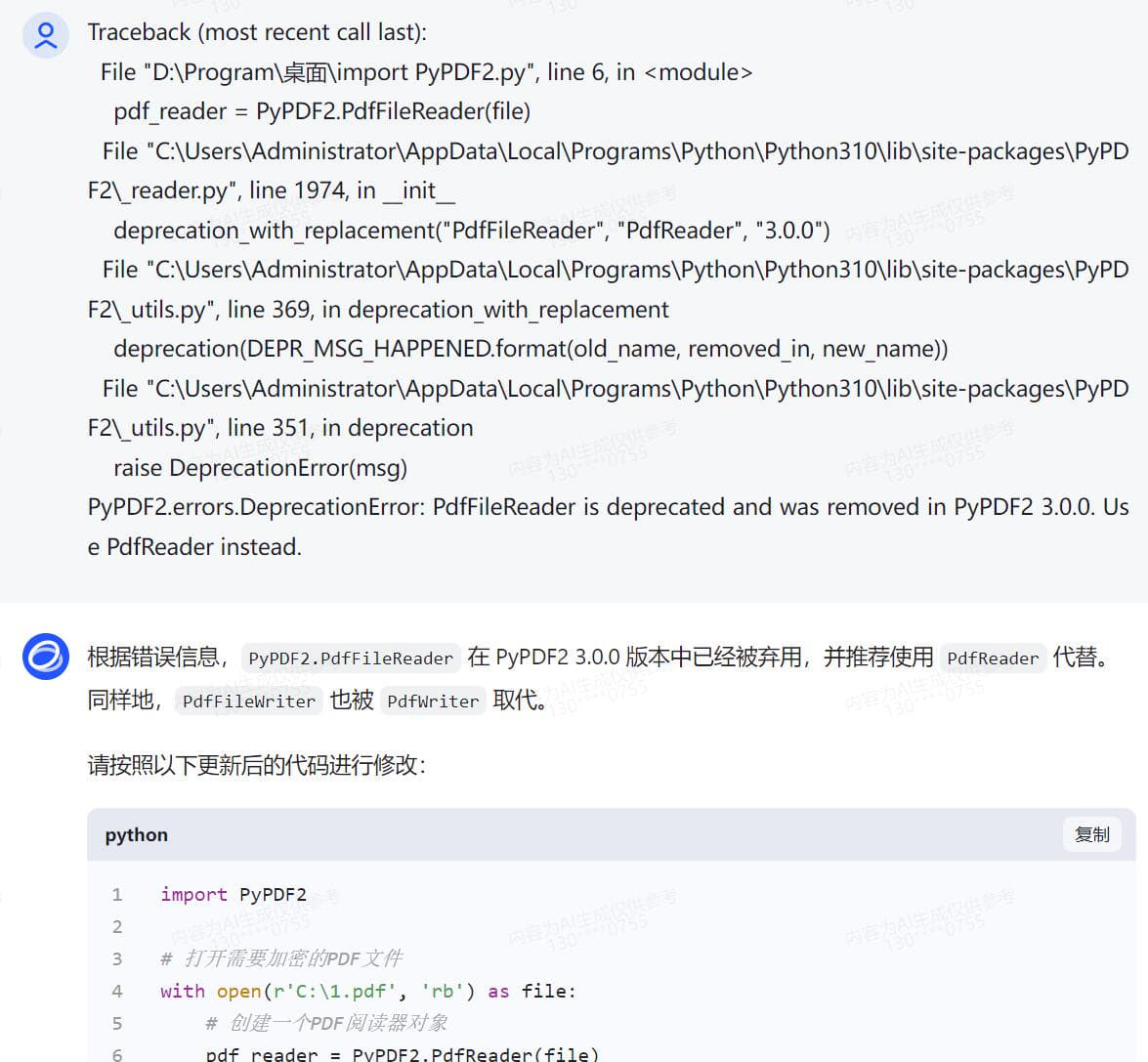 此时基础代码已可执行,且功能验证OK 只是需要直接在代码中注明需要加密的pdf和其路径,以及加密后的文件输出路径以及文件名 还有密码也是固定写在代码中的,这肯定是不合适的,因为pdf文档名称和路径都会变化,且密码也是会跟着变化的 而且代码运行时没有窗口,很不方便 好,再次整理一下我的需求并告诉AI接下来需要做哪些改进 根据AI返回的信息,我们还需要安装窗口GUI的模块 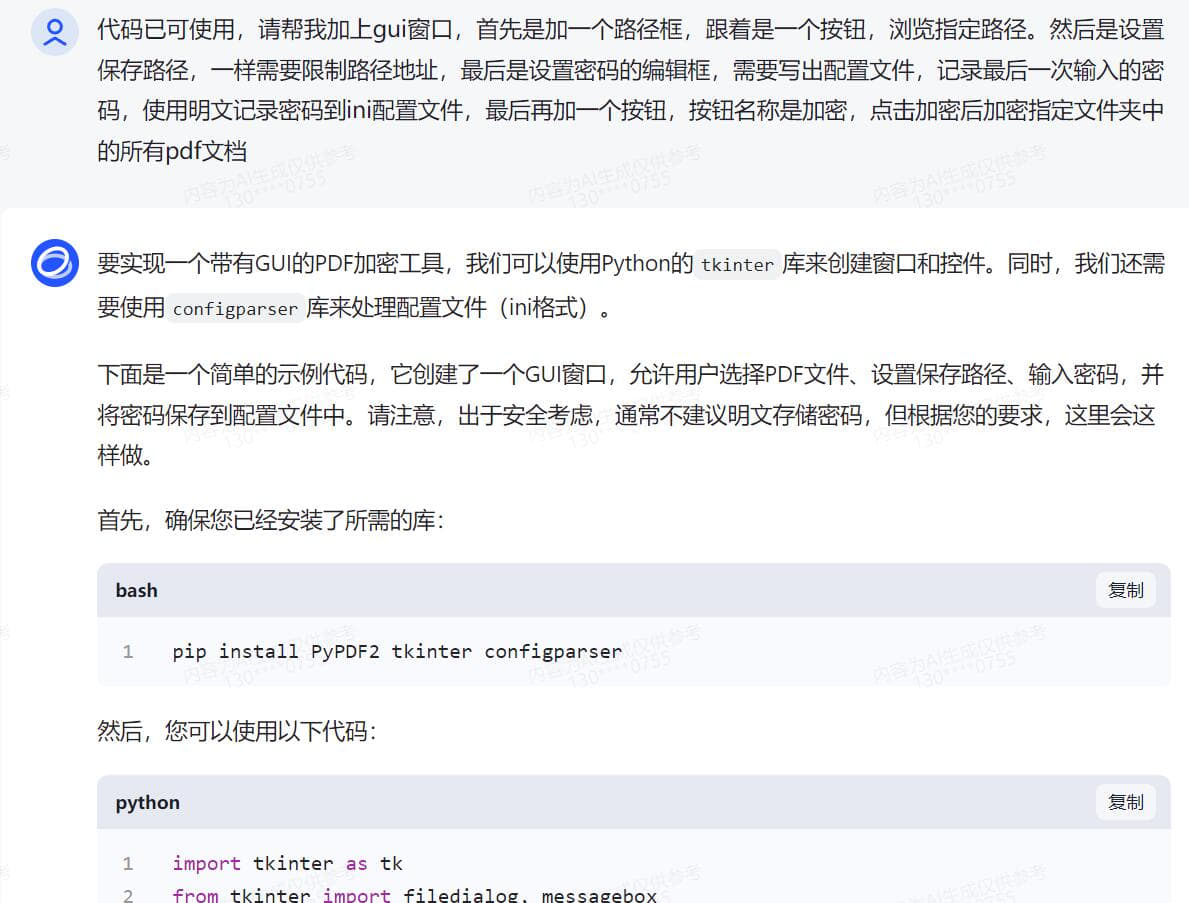 在安装模块时报错了,直接复制报错信息丢给AI 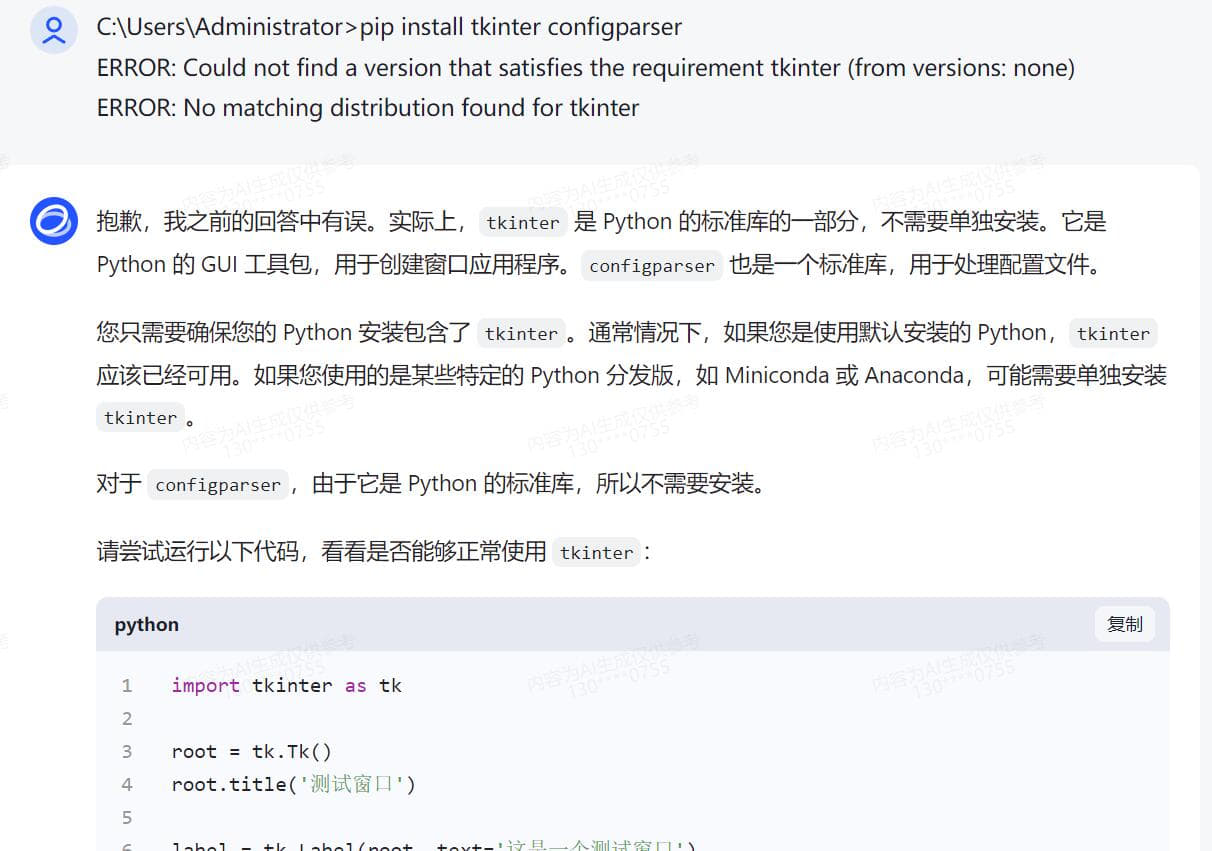 AI再次返回代码,运行时依然报错 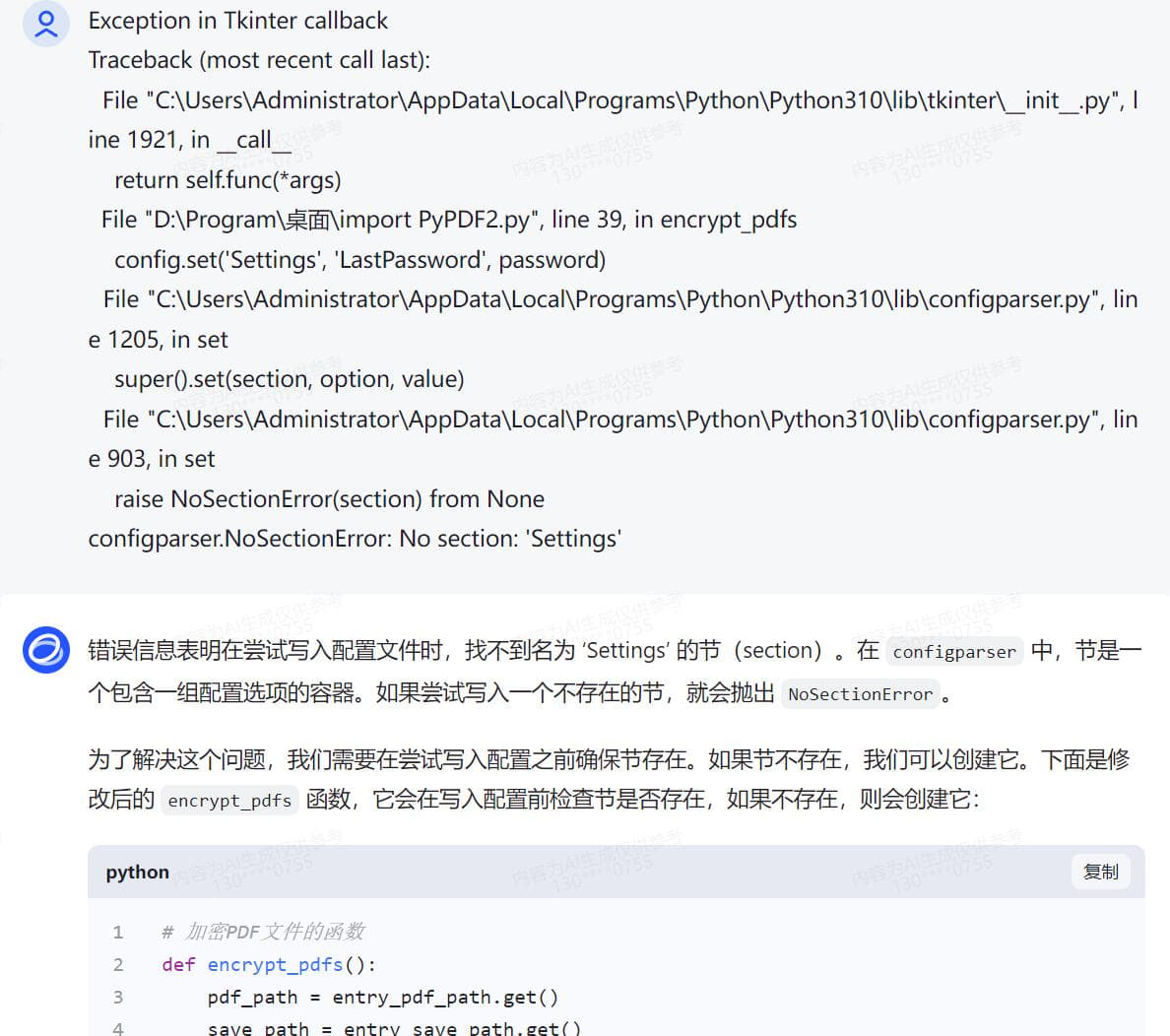 此时新的代码片段可以运行了,但是与实际需求还有一点点出入,此时可以将需求细化 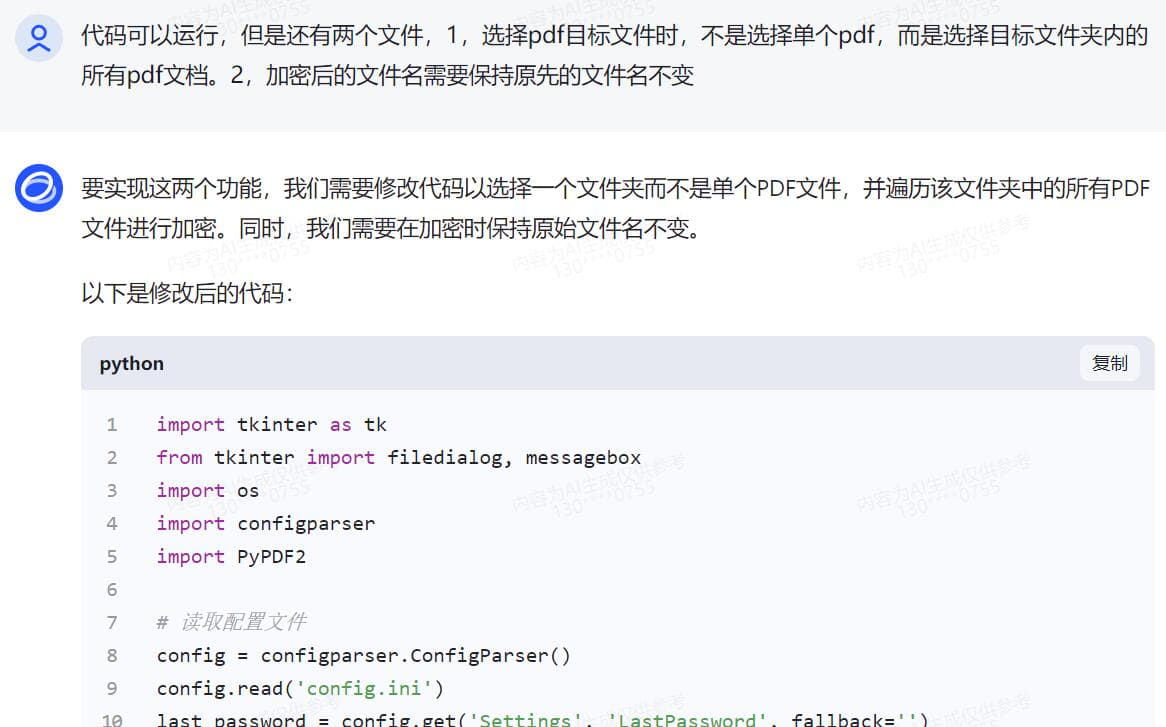 代码继续报错  代码基本满足需求,由于我是加密端,因此我需我看到的密码是明文,而不是一串***** 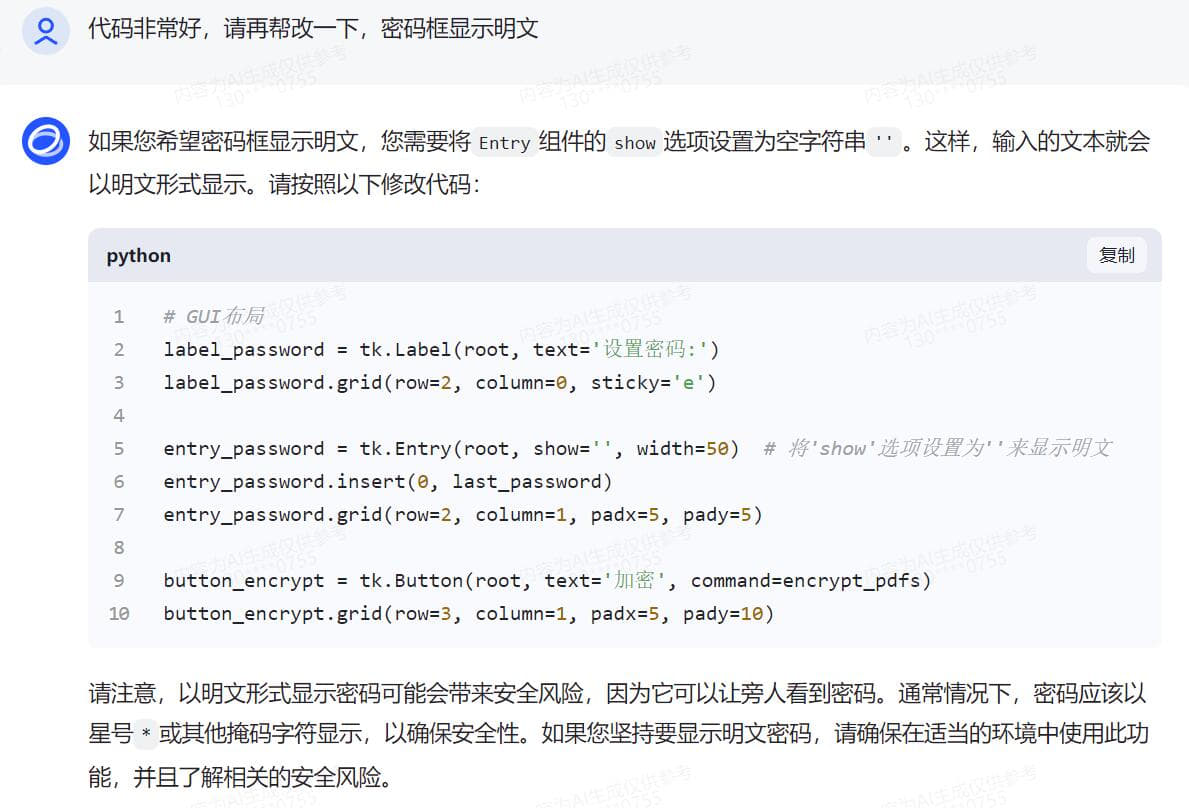 经过测试,所有功能满足我的需求,现在我需要将这段代码打包成exe单文件,便于二次分发 小知识,什么叫做二次分发? 意思是,这个代码在我电脑运行肯定是没有问题的,因为我电脑安装了Python,且本段代码所有依赖的模块也安装了 如果我把这个代码给到其他人,其他人不一定安装了Python,就算安装了Python,可能各种模块又需要重新安装一次 对于没有电脑基础的,这个门框稍高 我打包成exe单文件后,直接把这个exe可执行文件发给其他人,其他人双击即可运行 不用安装Python和各种依赖模块 打包工具也有很多,这里就不一一介绍,如有需要,请自行百度或者问AI 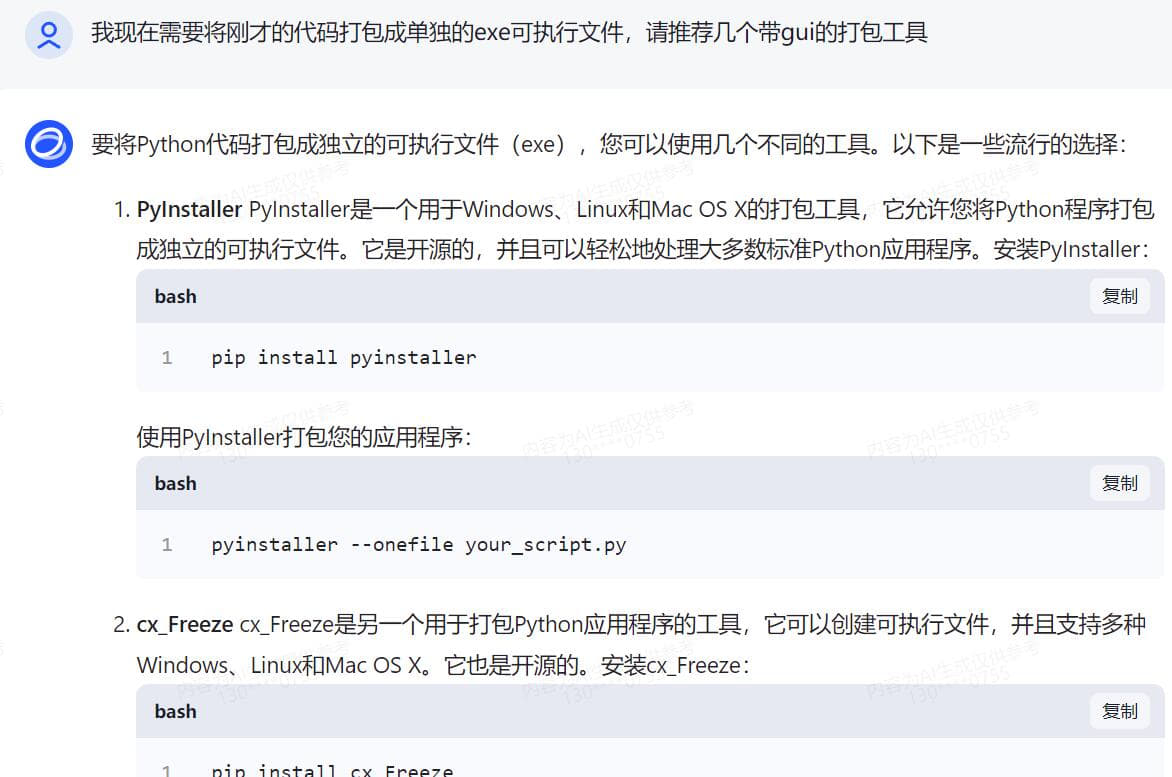 以下附上完整代码 [PDF加密工具.rar](/usr/uploads/2024/03/2060048501.rar)







网站版权本人所有,你要有本事,盗版不究。 sam@gpcb.net